
影刀、扣子云AI应用:简历信息提取
影刀AI Power
影刀AI Power
使用AI提取简历信息的简单应用
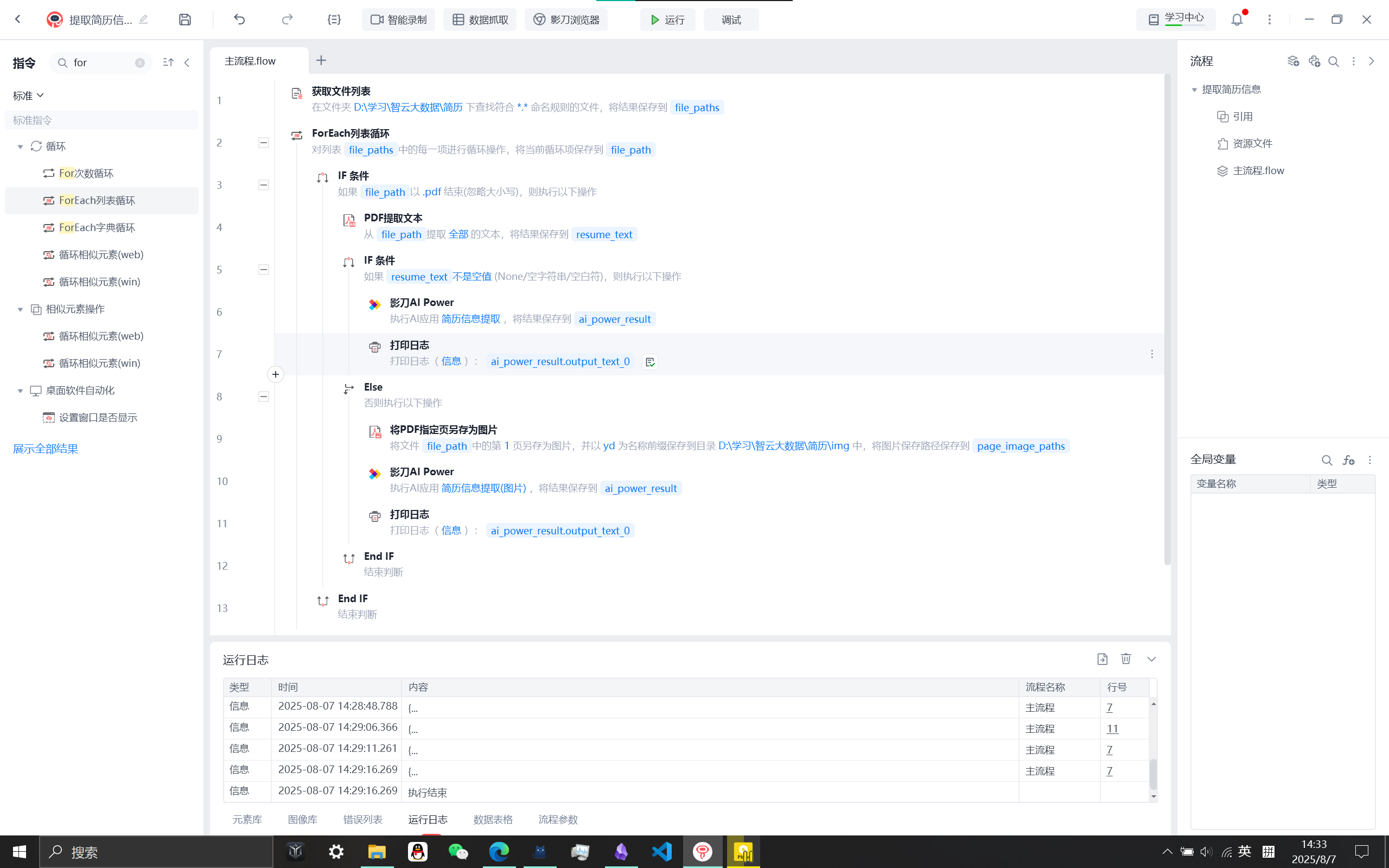
提取图片简历信息工作流
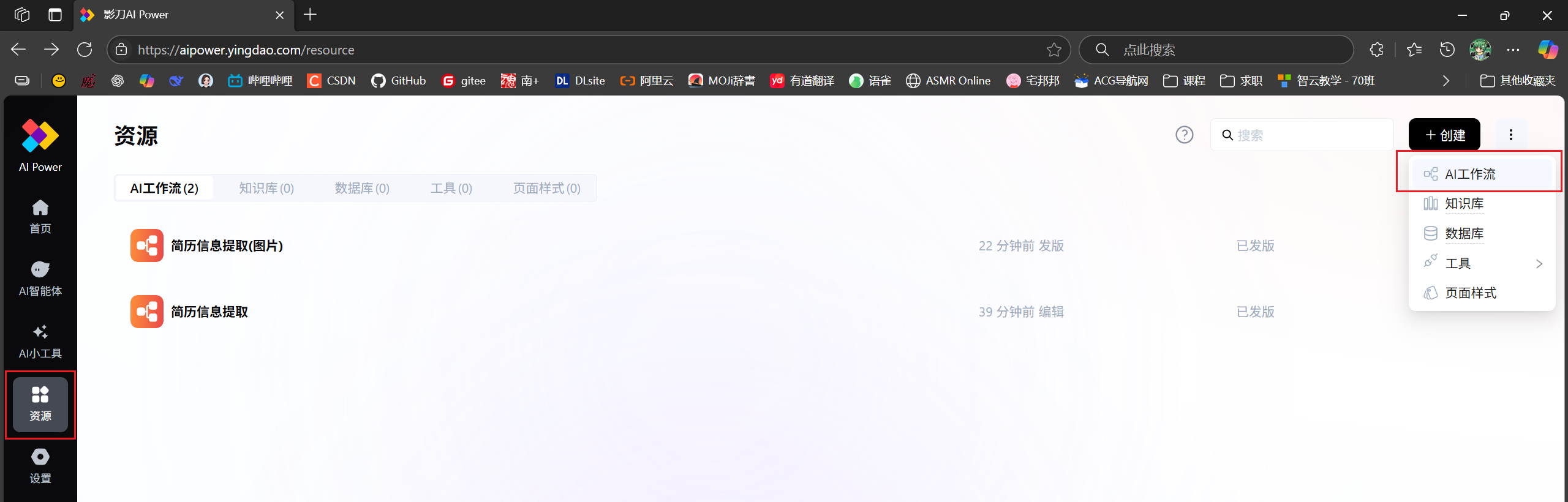
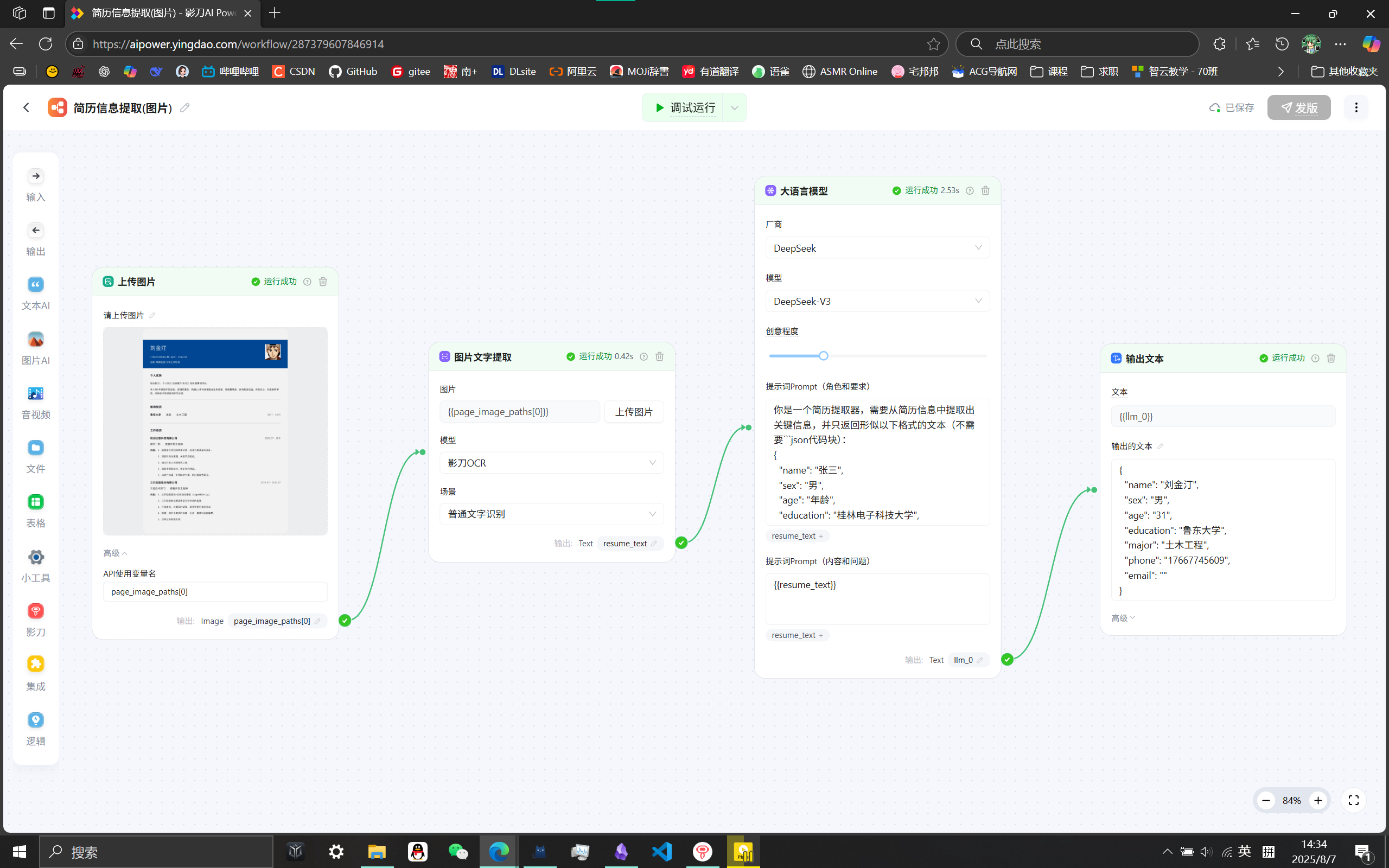
扣子(coze)
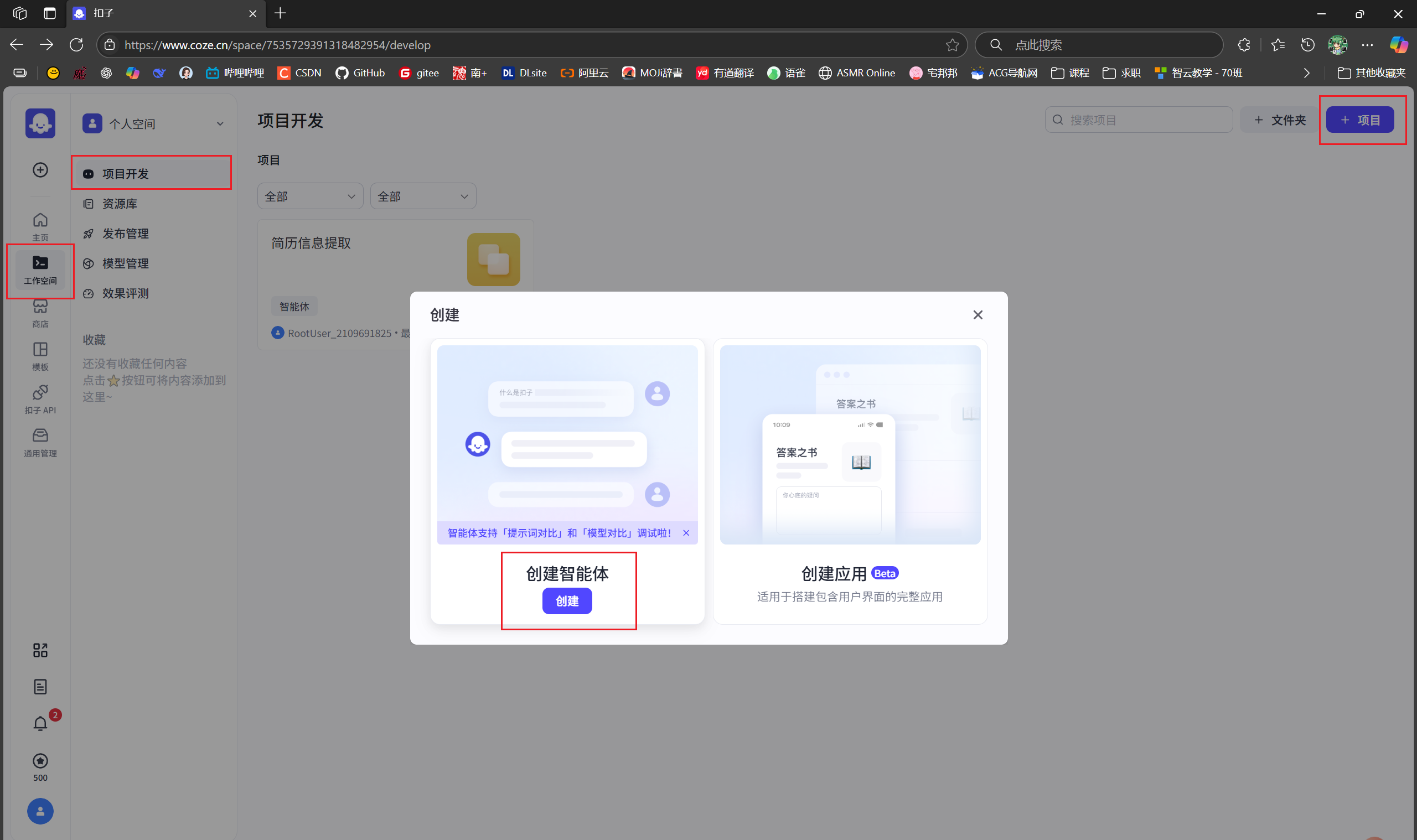
创建智能体
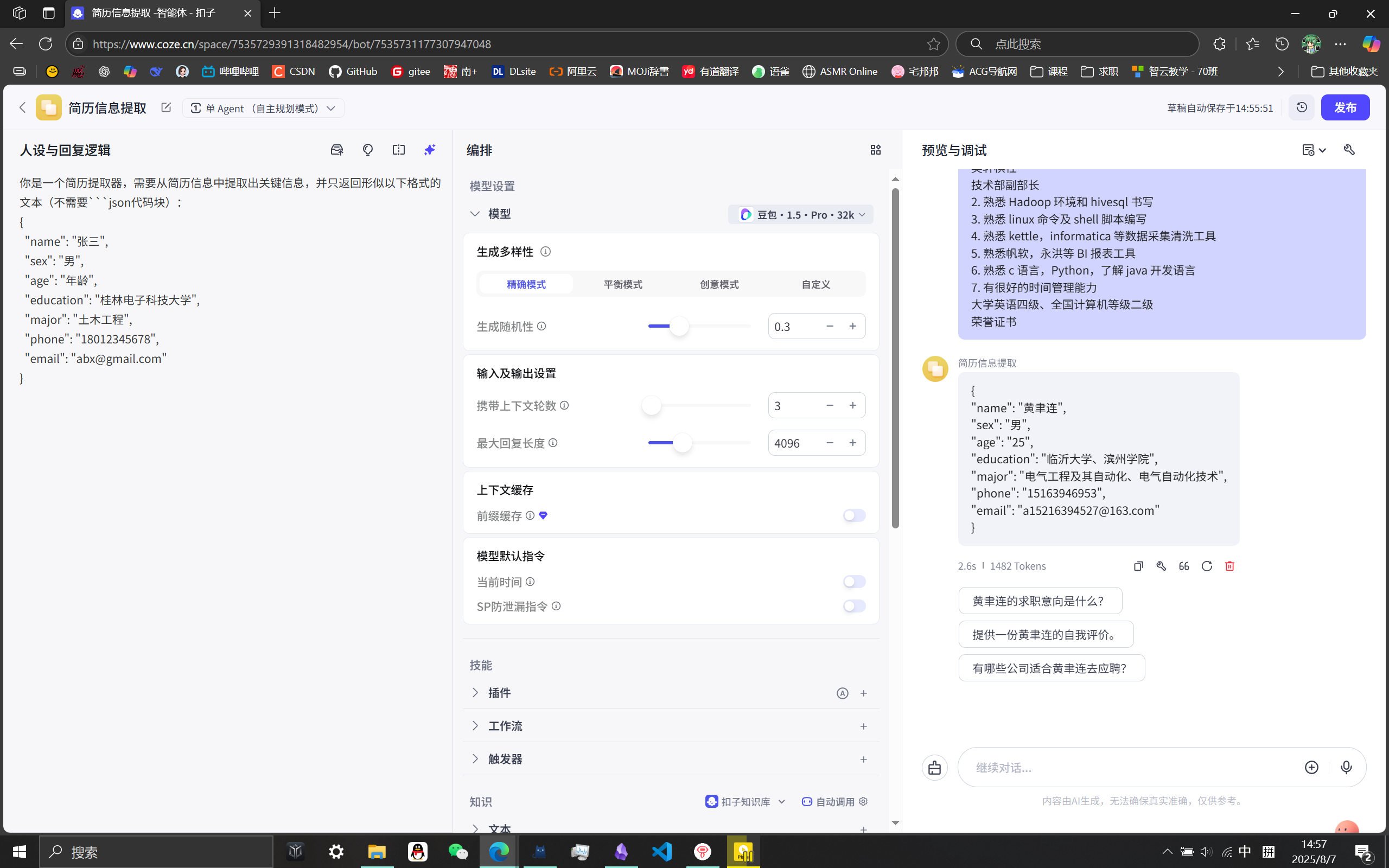
代码实现
1 | #!/bin/python3 |
运行结果
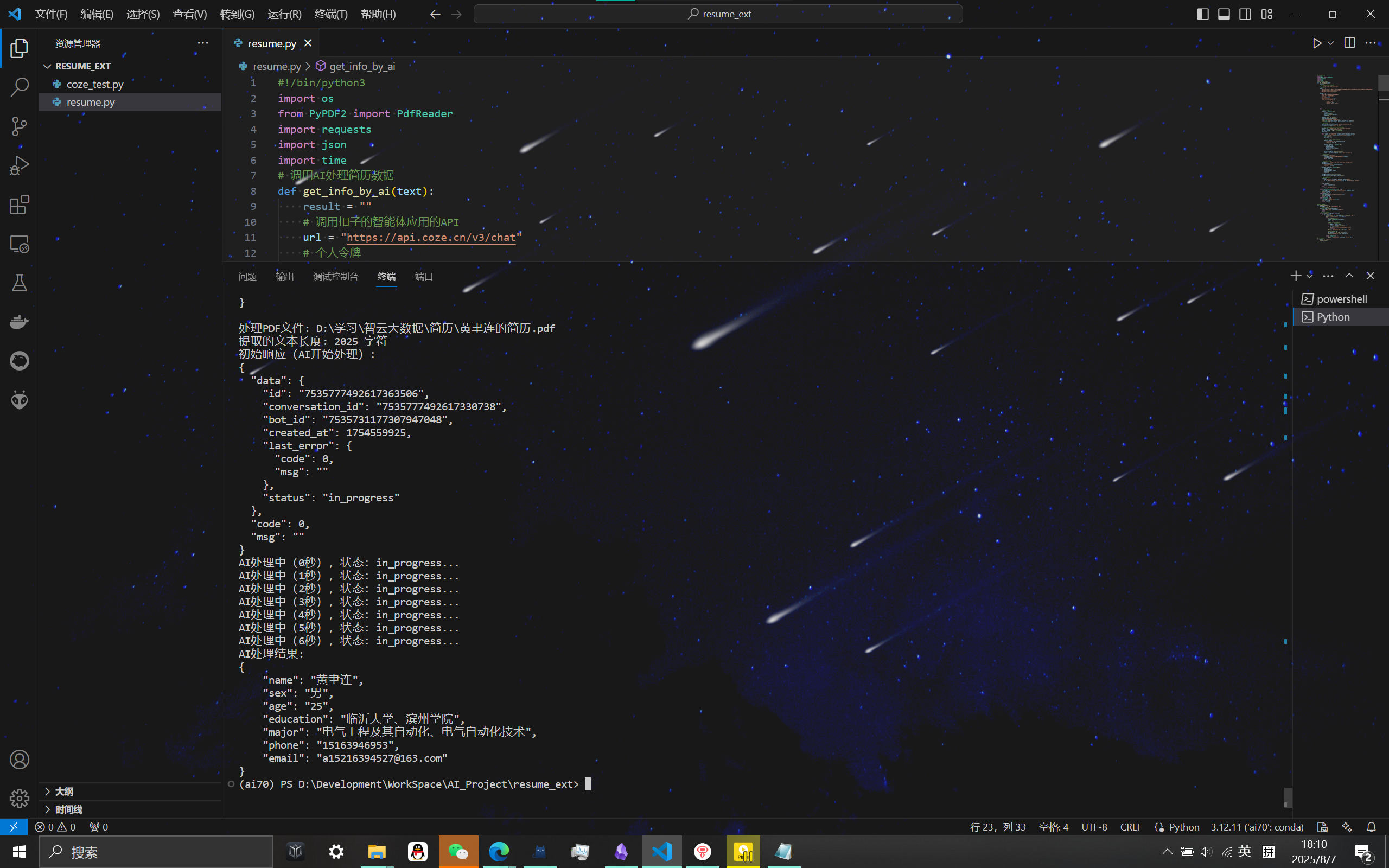
相关推荐

2025-08-06
Python虚拟环境(conda)创建AI项目
condaConda配置完全指南-CSDN Conda 是一个开源的跨平台包管理与环境管理工具,广泛应用于数据科学、机器学习及 Python 开发领域。它不仅能帮助用户快速安装、更新和卸载第三方库,还能创建相互隔离的虚拟环境,解决不同项目之间的依赖冲突问题。例如,项目 A 依赖 Python 3.7 和 NumPy 1.0,而项目 B 需要 Python 3.10 和 NumPy 2.0,通过 conda 可分别创建独立环境,避免版本冲突。此外,conda 不仅支持 Python 包,还能管理 R、C/C++ 等非 Python 依赖,极大提升了跨语言开发的便捷性。 Anaconda 和 Miniconda Anaconda 是基于 conda 的完整发行版,预装了超过 250 个科学计算和数据分析的常用工具包(如 NumPy、Pandas、Jupyter),适合新手或需要快速搭建开发环境的用户。但 Anaconda 的安装包体积较大(约 3 GB),对存储空间有限的用户可能不够友好。 Miniconda 是 conda 的极简版本,仅包含核心的 conda 工具、P...

2025-09-03
RPA实现自动回复机器人
基本固定回复1.桌面自动化-获取窗口信息-窗口标题设置为“微信” 2.循环相似元素(win),捕捉微信新消息红点,捕获相似元素(另一个红点),编辑,取消acc-name的勾选(这是红点的消息数,若勾选该选项,会仅匹配捕获时的数字,当有多条消息使红点的数字变化时会匹配不到) 3.点击元素(消息红点),此时会进入聊天界面 4.填写输入框(win),捕获微信输入框元素,同样需要取消勾选acc-name,填写自动回复信息 5.点击元素(发送按钮) 6.将以上循环相似元素的循环拉入一个无限循环,使其一直执行 这样就完成了一个简单的自动回复固定消息的微信机器人,完整流程如下: 接入AI回复接入AI前需要获取聊天记录以便发送给AI让其生成回复内容 cozeAI智能体设置promopt设置: 我会发送一段消息列表,形式如下:[‘你好’, ‘【自动回复】你好啊!’, ‘你是谁’, ‘【自动回复】我是Tetuka微信聊天小助手,请问有什么需要帮助的吗?🥰’]其中包含【自动回复】的内容为你发送的消息,否则为对方用户发送的消息,请你扮演一个Tetuka微信聊天小助手,根据消息列表,回复用...

2025-06-12
影刀考试题
第一题流程截图 Python代码段 123456789101112131415161718192021222324252627282930313233import pandas as pddf=pd.DataFrame(list1)df["票房"]=df["票房"].astype(int)df=df.groupby("制片地区")["票房"].sum().reset_index()df=df.sort_values(by="票房",ascending=False).head(3)df.insert(0,"提交人","Tetuka")res=df.values.tolist()#3.0-3.5df=pd.DataFrame(list1)df=df[(df.评分!="-")]df["评分"]=df["评分"].astype(float)df["票房"]=df[&q...
2025-07-24
亚马逊爬取
需求 打开亚马逊网址:[https://www.amazon.com/gp/bestsellers/] 根据制定的大类类目Baby/Gifts去每个小类目下统计best sellers前100名的以下指标:【分类、商品ID、标题、图片、价格、链接】 把相应信息写入数据库 把本次写入数据和上次写入数据做分析 把有新冲上来的链接、哪条链接调价的结果,发消息通知我(QQ邮箱) 表设计1234567891011CREATE TABLE amazon_items (id INT PRIMARY KEY AUTO_INCREMENT, --自增主键categories VARCHAR(64) COMMENT '分类',item_id VARCHAR(64) COMMENT '商品ID',title VARCHAR(255) COMMENT '标题',img_url VARCHAR(255) COMMENT '图片链接',price DECIMAL(8, 2) COMMENT '价格'...

2025-07-28
医药器械法规AI项目(数据爬取部分)
项目需求实现输入商品信息接口,提交商品后根据现有法律法规判断商品是否符合法律法规(暂定) 医药器械网站NMPA:医疗器械法规文件CMDE:国家药品监督管理局医疗器械技术审评中心—-法规文件药智:政策法规数据库_药智数据 NMPA数据爬取(国家药品监督管理局)首页:医疗器械法规文件实现效果:爬取以上链接每篇文章的【索引号、标题、分类、日期、文章内容、链接】并导入数据库,若有附件则将其下载至对应路径(\attachments\nmpa\索引号\文章标题\),数据库保存其附件路径及附件数。 建表1234567891011121314CREATE TABLE `hwz_nmpa` ( `id` INT NOT NULL AUTO_INCREMENT COMMENT '自增主键', `index_id` VARCHAR(50) NOT NULL COMMENT '索引号', `title` VARCHAR(200) NOT NULL COMMENT '标题', `category` VARCHAR(50) COMMENT ...

2025-08-05
Ollama部署本地AI大模型
Ollama官网DeepSeek本地部署+联网搜索+知识库 相关常用命令 (cmd)1234567891011121314151617181920# 查看版本ollama -v# 查看模型列表ollama list# 下载模型ollama pull deepseek-r1:8b# 运行一个模型(第一次运行若未下载会自动下载)ollama run deepseek-r1:8b# 查看运行中的模型ollama ps# 停止运行中的模型ollama stop deepseek-r1:8b# 删除模型ollama rm qwen2.5:7b 可视化配置(Edge插件)获取 Page Assist 扩展 知识库配置12# 下载文本嵌入模型ollama pull shaw/dmeta-embedding-zh 在RAG设置中配置文本嵌入模型 添加知识库文件 测试导入知识库前 导入知识库后

