SparkSQL Spark SQL 是 Apache Spark 生态系统中的一个核心模块,专门用于处理结构化数据。它为用户提供了使用 SQL 语句或 DataFrame API 来查询和操作数据的能力,极大地简化了大数据分析任务的开发流程。
一、Spark SQL 的核心特点
统一的数据访问方式
JSON、Parquet、ORC、CSV 等文件格式
JDBC/ODBC 接口连接传统数据库(如 MySQL、PostgreSQL)
Hive 表(通过 HiveContext)
Kafka 流数据(结合 Structured Streaming)
SQL 支持
1 SELECT name, age FROM people WHERE age > 30
这使得熟悉 SQL 的数据分析师可以轻松上手。
DataFrame 和 Dataset API
DataFrame :以结构化方式组织的分布式数据集,类似于传统数据库中的表或 Pandas 中的 DataFrame。Dataset (仅在 Scala/Java 中):类型安全的 DataFrame,结合了对象模型和函数式编程的优势。
Catalyst 优化器
Tungsten 引擎
与 Spark 生态无缝集成
二、Spark SQL 的架构
SQL Parser :解析 SQL 语句,生成抽象语法树(AST)。Analyzer :结合元数据(如 Hive Metastore 或内置 Catalog)解析未绑定的逻辑计划。Optimizer (Catalyst) :使用规则优化逻辑计划。Planner :将逻辑计划转换为多个物理执行计划。Cost-based Optimizer :选择最优的物理执行计划。Execution Engine :在集群上执行最终的物理计划。
三、使用示例 1. 使用 Spark SQL 查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pyspark.sql import SparkSessionspark = SparkSession.builder \ .appName("SparkSQLExample" ) \ .getOrCreate() df = spark.read.json("people.json" ) df.createOrReplaceTempView("people" ) result = spark.sql("SELECT name, age FROM people WHERE age > 30" ) result.show()
2. 使用 DataFrame API 1 df.filter (df.age > 30 ).select("name" , "age" ).show()
四、应用场景
数据仓库查询 :替代 Hive 做更高效的批处理查询。ETL 处理 :清洗、转换、加载结构化数据。交互式分析 :结合 BI 工具(如 Tableau、Superset)进行可视化分析。流批一体 :通过 Structured Streaming 实现实时 SQL 查询。
五、优势与局限
优势
局限
高性能(得益于 Catalyst 和 Tungsten)
学习曲线较陡(尤其 Catalyst 内部机制)
支持标准 SQL 和多种数据源
相比专用数据库(如 ClickHouse),实时分析延迟仍较高
易于与 Spark 生态集成
资源消耗较大,适合中大规模数据处理
支持 Schema 演化和复杂数据类型(如 Array、Struct)
小文件处理效率较低
六、总结 Spark SQL 是大数据领域中最重要的 SQL 引擎之一,它将 SQL 的易用性与 Spark 的分布式计算能力相结合,广泛应用于数据湖分析、数据仓库、实时流处理等场景。对于需要处理 TB 到 PB 级结构化或半结构化数据的团队,Spark SQL 是一个强大而灵活的选择。在使用 Hadoop、Hive 或需要构建数据湖(Data Lake)这些场景下,Spark SQL 往往是首选的查询引擎之一。
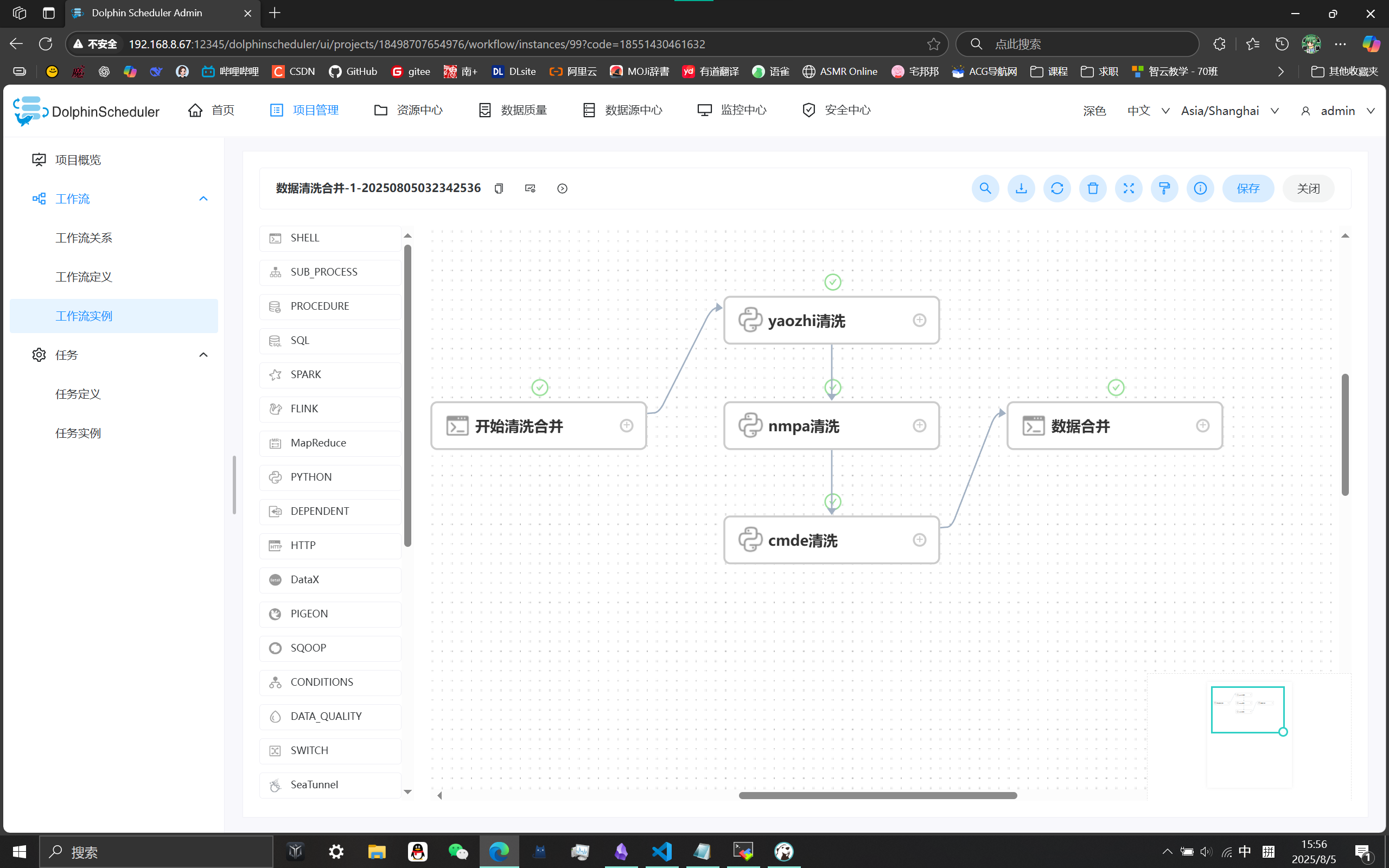
项目实例 清洗数据(DWD层) ODS => DWD 数据清洗
清洗流程图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 graph TD 清洗规则-->|可以修复|修复数据; 清洗规则-->|无法修复|删除数据; 删除数据-->非nmpa网站的数据; 修复数据-->附件检测; 附件检测-->下载成功; 附件检测-->下载失败; 下载成功-->存在附件文件; 存在附件文件-->上传到HDFS-/zhiyun/huangwenzhe/attacments/nmpa/...; 存在附件文件-->文本识别; 文本识别-->word文档; 文本识别-->pdf文档; word文档-->文本类型-现成的库处理; pdf文档-->文本类型-现成的库处理; pdf文档-->扫描类型-OCR识别;
识别附件内容追加到内容字段(content) 提取word文字: https://www.cnblogs.com/Yesi/p/17911301.html https://blog.51cto.com/u_16175497/6731114 python跨平台读取 .doc 格式文件靠谱的做法-CSDN博客
提取pdf文字: https://blog.csdn.net/stephenzyx/article/details/129974065 https://cloud.tencent.com/developer/article/2323682
python清洗脚本 yaozhi.py (仅处理yaozhi的数据,其他每个表各写一个py脚本,但总体结构差不多)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 import jsonimport reimport osimport globfrom pyspark.sql import SparkSessionfrom pyspark.sql import functions as Ffrom pyspark.sql.types import StringTypefrom PyPDF2 import PdfReader from docx import Document import subprocess spark = SparkSession.builder \ .master("local[*]" ) \ .appName("app" ) \ .config('spark.driver.memory' , '6g' ) \ .config('spark.executor.memory' , '6g' ) \ .config('spark.local.dir' , '/home/spark-tmp' ) \ .config('spark.sql.parquet.writeLegacyFormat' , 'true' ) \ .config("hive.metastore.uris" , "thrift://hdp:9083" ) \ .enableHiveSupport() \ .getOrCreate() @F.udf(StringType( ) def get_platform_id (link ): if not link: return "" parts = link.rstrip('/' ).split('/' ) if not parts: return "" filename = parts[-1 ] if filename.endswith('.html' ): id_part = filename[:-5 ] if id_part.isdigit(): return id_part return "" @F.udf(StringType( ) def get_attachment_text (attachment_path ): if not attachment_path: print ("未提供附件路径" ) return "" try : linux_path = re.sub( r'^D:\\WorkSpace\\RPA_project\\attachments' , '/zhiyun/huangwenzhe/data/attachments' , attachment_path ) linux_path = linux_path.replace('\\' , '/' ) if not os.path.exists(linux_path): print (f"错误:路径不存在 - {linux_path} " ) return "" attachments = [] if os.path.isdir(linux_path): for ext in ['*.doc' , '*.docx' , '*.pdf' ]: attachments.extend(glob.glob(os.path.join(linux_path, ext), recursive=False )) else : if linux_path.lower().endswith(('.doc' , '.docx' , '.pdf' )): attachments.append(linux_path) if not attachments: return "" all_text = [] for file_path in attachments: try : file_ext = file_path.lower().split('.' )[-1 ] filename = os.path.basename(file_path) text = "" if file_ext == 'docx' : doc = Document(file_path) full_text = [] for para in doc.paragraphs: full_text.append(para.text) text = '\n' .join(full_text) elif file_ext == 'doc' : try : print (f"尝试使用 catdoc 处理文件: {file_path} " ) result = subprocess.run( ["catdoc" , "-w" , "0" , "-d" , "utf-8" , file_path], capture_output=True , text=True , encoding='utf-8' , errors='ignore' ) if result.returncode == 0 : text = result.stdout print (f"catdoc 处理完成: {result.stdout[:50 ]} ..." ) else : print (f"catdoc 处理失败 ({result.returncode} ): {result.stderr} " ) text = "" except Exception as e: print (f"调用 catdoc 出错: {str (e)} " ) text = "" elif file_ext == 'pdf' : reader = PdfReader(file_path) text = "" for page in reader.pages: page_text = page.extract_text() if page_text: text += page_text + "\n" all_text.append(f"[文件: {filename} ]\n{text} \n" ) except Exception as e: print (f"[文件: {filename} 处理失败: {str (e)} ]\n" ) return '\n' .join(all_text) except Exception as e: print (f"处理附件时出错: {str (e)} " ) return "" sql = ''' select id, "" as platform_id, title, dept, post_date, zihao, level, timeliness, content, link, attachment_path, create_time, update_time from ods_huangwenzhe.yaozhi ; ''' df = spark.sql(sql) df = df.withColumn("platform_id" , get_platform_id("link" )) df = df.withColumn( "content" , F.concat( F.col("content" ), F.lit("\n\n[附件内容开始]\n\n" ), get_attachment_text("attachment_path" ), F.lit("\n\n[附件内容结束]" ) ) ) df.show() os.system("hadoop fs -mkdir -p /zhiyun/huangwenzhe/dwd/yaozhi" ) os.system(''' hive -e "create database if not exists dwd_huangwenzhe location '/zhiyun/huangwenzhe/dwd'" ''' ) df.write.format ("hive" ) \ .mode("overwrite" ) \ .option("fileFormat" ,"parquet" ) \ .option("location" ,"/zhiyun/huangwenzhe/dwd/yaozhi" ). \ saveAsTable("dwd_huangwenzhe.yaozhi" ) print ("\n清洗完成" )
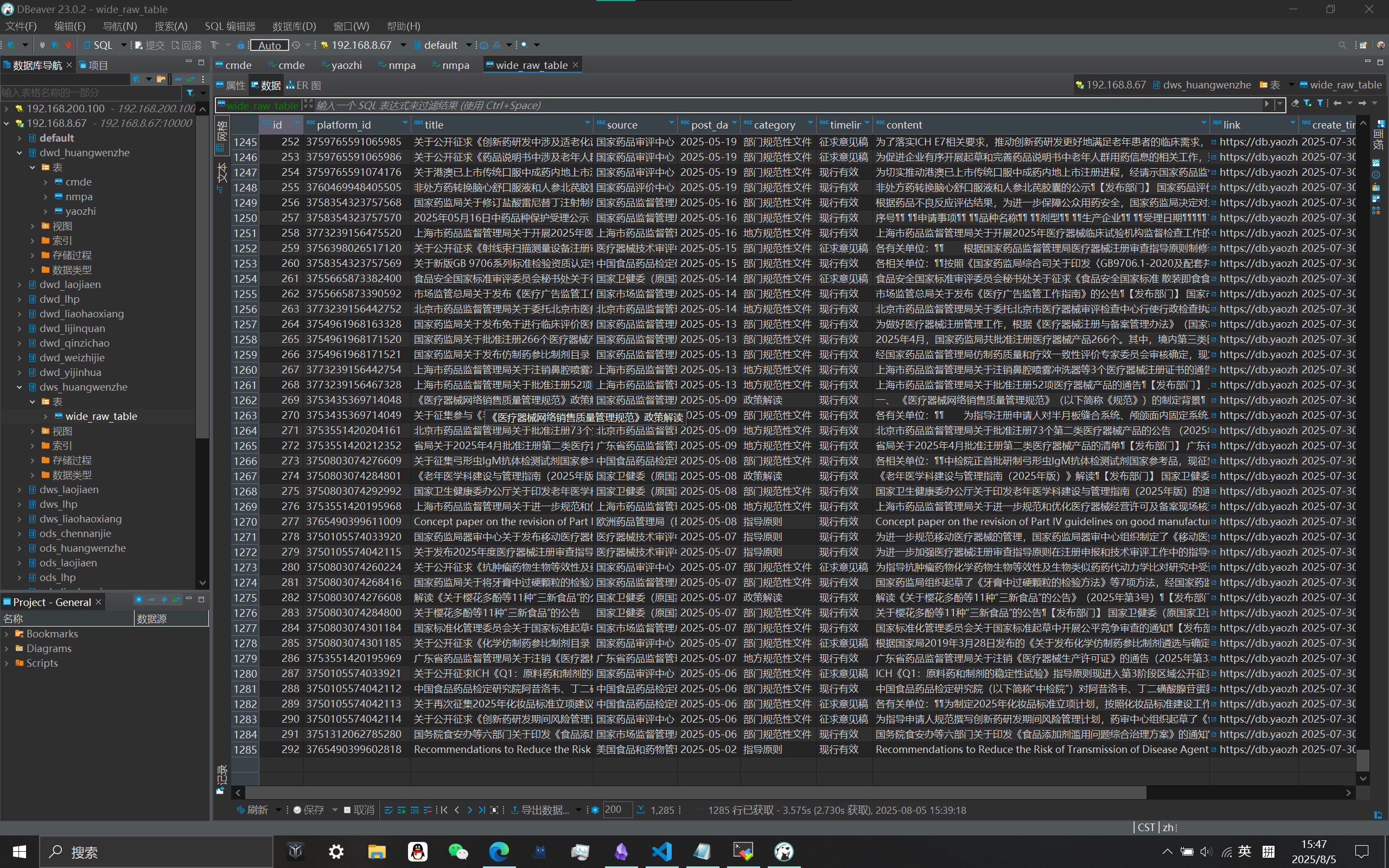
合并数据(DWS层) DWD => DWS 宽表加工
要求: 把清洗好的各平台数据表合并成一张大表, 该表应该包含数据表的所有字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 create table if not exists dws_huangwenzhe.wide_raw_table(id int ; platform_id string, title string, source string, post_date string, category string, timeliness string, content string, link string, create_time string update_time string ) partitioned by (platform string);
bash脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 #!/bin/bash set -e log echo "[$(date +'%Y-%m-%d %H:%M:%S') ] $1 " } log "创建宽表HDFS存储路径..." hadoop fs -mkdir -p /zhiyun/huangwenzhe/dws/wide_raw_table log "创建dws层数据库..." hive -e " create database if not exists dws_huangwenzhe location '/zhiyun/huangwenzhe/dws'; " log "创建宽表结构..." hive -e " create table if not exists dws_huangwenzhe.wide_raw_table( id int, platform_id string, title string, source string, post_date string, category string, timeliness string, content string, link string, create_time string, update_time string ) partitioned by (platform string) stored as parquet location '/zhiyun/huangwenzhe/dws/wide_raw_table'; " log "插入yaozhi数据到宽表..." hive -e " insert overwrite table dws_huangwenzhe.wide_raw_table partition(platform='yaozhi') select id, platform_id, title, dept as source, post_date, level as category, timeliness, content, link, create_time, update_time from dwd_huangwenzhe.yaozhi where title is not null and content is not null; " log "插入nmpa数据到宽表..." hive -e " insert overwrite table dws_huangwenzhe.wide_raw_table partition(platform='nmpa') select id, index_id as platform_id, title, null as source, post_date, category, null as timeliness, content, link, create_time, update_time from dwd_huangwenzhe.nmpa where title is not null and content is not null; " log "插入cmde数据到宽表..." hive -e " insert overwrite table dws_huangwenzhe.wide_raw_table partition(platform='cmde') select id, platform_id, title, source, post_date, null as category, null as timeliness, content, link, create_time, update_time from dwd_huangwenzhe.cmde where title is not null and content is not null; " log "所有平台数据合并到宽表成功!"
若想提高插入效率可将三个查询语句用union all拼接,此处为了方便排错调试故拆开
自动化调度 使用海豚调度平台将以上内容整合成一个工作流定时执行海豚调度平台
结果验证