
医药器械法规AI项目(数据爬取部分)
项目需求
实现输入商品信息接口,提交商品后根据现有法律法规判断商品是否符合法律法规(暂定)
医药器械网站
NMPA:医疗器械法规文件
CMDE:国家药品监督管理局医疗器械技术审评中心—-法规文件
药智:政策法规数据库_药智数据
NMPA数据爬取(国家药品监督管理局)
首页:医疗器械法规文件
实现效果:爬取以上链接每篇文章的【索引号、标题、分类、日期、文章内容、链接】并导入数据库,若有附件则将其下载至对应路径(\attachments\nmpa\索引号\文章标题\),数据库保存其附件路径及附件数。
建表
1 | CREATE TABLE `hwz_nmpa` ( |
Python代码流程
分页抓取
get_list()遍历分页(index.html、index_1.html…),提取每页的标题和链接。- 关键点:分页逻辑(第1页无编号,后续页为
index_{n-1}.html),每页间隔 2 秒防反爬。
详情页解析
get_page()解析单篇文章,提取:- 核心字段:索引号(
index_id)、标题、分类、日期、正文内容。 - 基础 URL:从链接拆解出
https://域名/,用于拼接附件的相对路径。
- 核心字段:索引号(
附件下载
download_attachments()处理附件:路径规范:
D:\...\nmpa\{index_id}\{安全标题}\(过滤特殊字符)。防重复:检查本地文件是否已存在,跳过已下载文件。
分块下载:
stream=True避免内存溢出,支持大文件。
数据存储
save_to_mysql()存入数据库:- 去重逻辑:通过
index_id + link判断记录是否存在,存在则更新,否则新增。 - 事务管理:出错时回滚(
rollback),确保数据一致性。
- 去重逻辑:通过
1 | import os |
效果验证


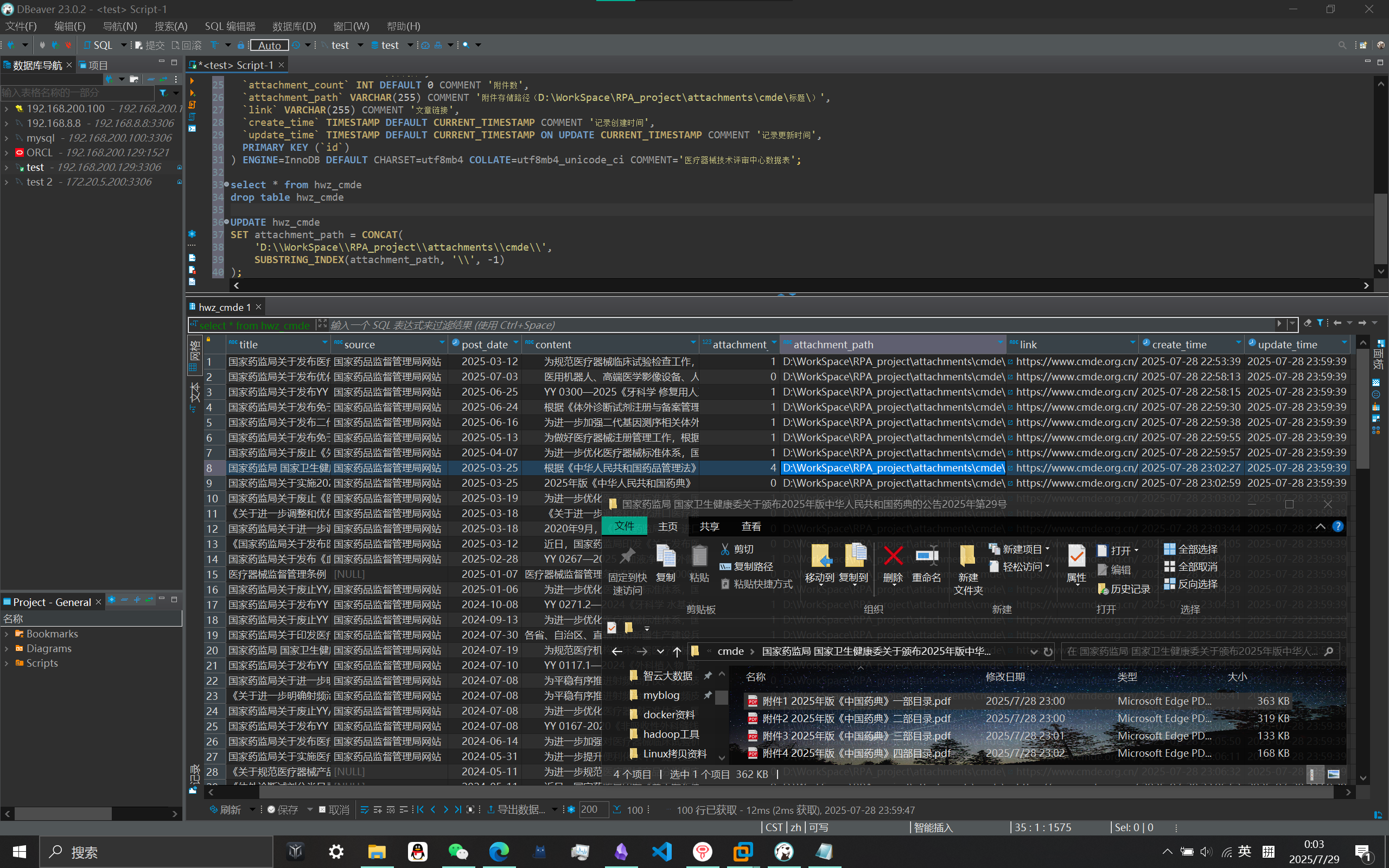
CMDE数据爬取(医疗器械技术评审中心)
首页:国家药品监督管理局医疗器械技术审评中心—-法规文件
实现效果:爬取以上链接每篇文章的【标题、文章来源、发布日期、文章内容、链接】并导入数据库,若有附件则将其下载至对应路径(\attachments\cmde\文章标题\),数据库保存其附件路径及附件数。
(为节省时间这里仅爬取5页作验证测试)
建表
1 | CREATE TABLE `hwz_cmde` ( |
Python代码流程
流程与nmpa一致,仅需对抓取方式及入库相关稍作修改
1 | import os |
效果验证
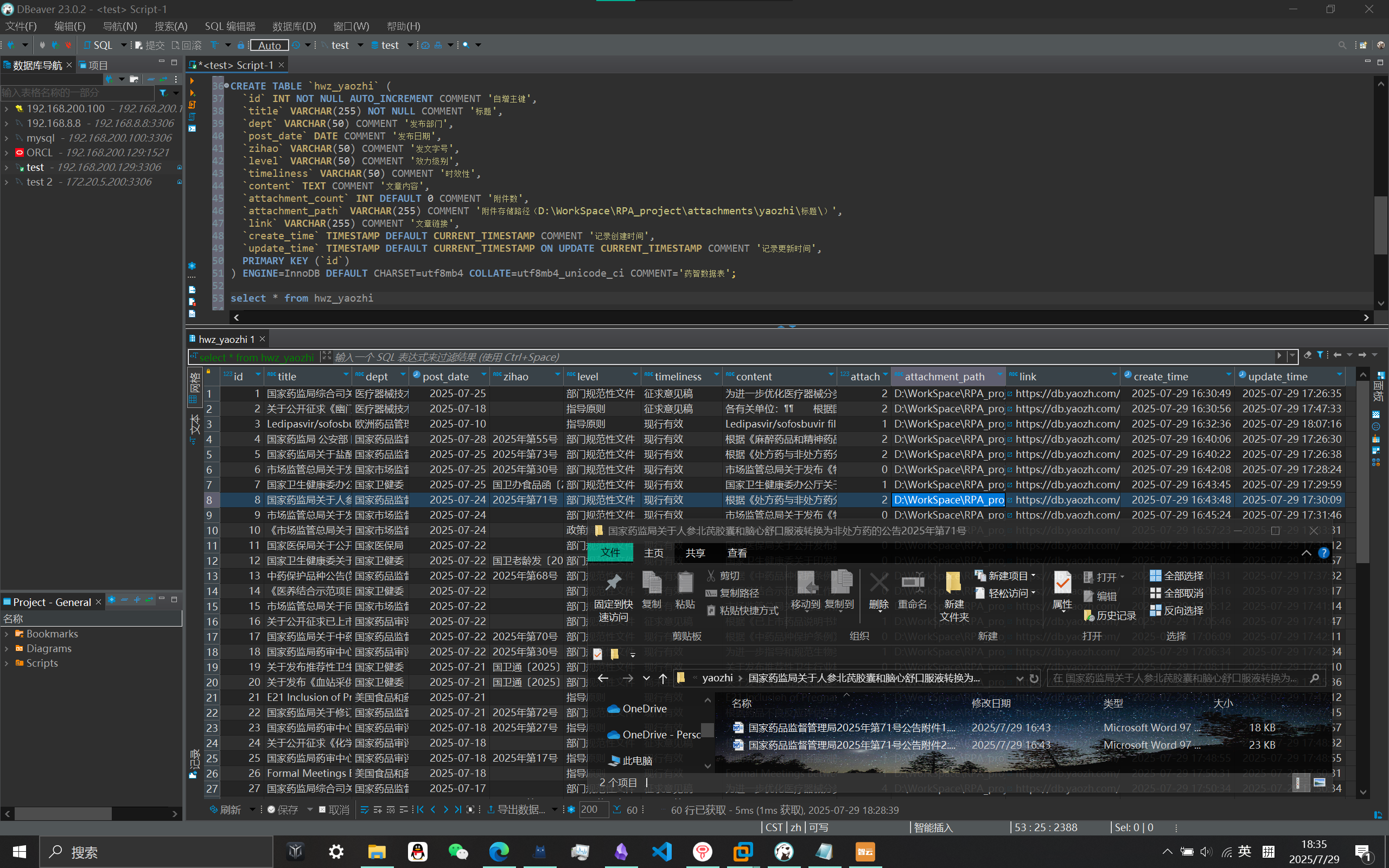
药智数据爬取
首页:政策法规数据库_药智数据
实现效果:爬取以上链接每篇文章的【标题、发布部门、发布日期、发文字号、效力级别、时效性、文章内容、链接】并导入数据库,若有附件则将其下载至对应路径(\attachments\yaozhi\文章标题\),数据库保存其附件路径及附件数。
建表
1 | CREATE TABLE `hwz_yaozhi` ( |
Python代码流程
列表页处理:
get_list()函数遍历指定页数的政策列表- 每页构建URL:
https://db.yaozh.com/policies?p={page}.html - 使用XPath定位表格行(
tr)元素 - 从每行提取4个关键信息:
- 标题
- 链接(拼接完整URL)
- 发布部门
- 发布日期
详情页处理:
- 对每个列表项调用
get_page() - 包含重试机制(最多4次尝试加载页面)
- 提取关键信息:
- 发文字号
- 效力级别
- 时效性
- 文章内容(多种尝试策略)
- 对每个列表项调用
附件处理:
- 调用
download_attachments()下载所有附件 - 创建安全目录名(过滤非法字符+长度限制)
- 下载PDF/DOC/XLS/ZIP/RAR格式文件
- 处理相对路径和文件名
- 调用
数据存储:
- 调用
save_to_mysql()保存所有数据到数据库 - 包含更新/插入逻辑(基于链接判断是否为同一条数据)
- 自动截断超长字段(标题255字符限制)
- 调用
1 | import os |
效果验证
相关推荐

2025-08-07
影刀、扣子云AI应用:简历信息提取
影刀AI Power影刀AI Power使用AI提取简历信息的简单应用 提取图片简历信息工作流 扣子(coze)主页 - 扣子API 介绍 - 文档 - 扣子 创建智能体 代码实现 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153#!/bin/python3import osfrom PyPDF2 import PdfRe...

2025-06-09
6.9总结:Pandas、爬虫
Python API 接⼝开发⽤法介绍API ( Application Programming Interface )是应⽤程序接⼝的简称 12345678910111213141516# 定义一个API接口@app.route("/")def index(): return "<a href='/list'><img src='/static/py11.png'></a>" # 定义一个API接口@app.route("/addSubmit", methods=["POST"])def addSubmit(): tid = request.form.get("tid") tname = request.form.get("tname") tcontent=request.form.get("tcontent") leixing=Mov...

2025-08-16
request和selenium(Python爬虫)
requests 和 selenium 是 Python 中两个常用的用于网络数据获取的工具,但它们的设计目标、使用场景和底层机制有显著不同。 入门指南 | Selenium 1. 基本概念 项目 requests selenium 类型 HTTP 库 浏览器自动化工具 功能 发送 HTTP 请求,获取响应 控制真实或虚拟浏览器进行页面操作 依赖 不依赖浏览器 依赖浏览器(如 Chrome、Firefox)或无头浏览器 2. 工作原理 requests: 直接与服务器进行 HTTP 通信。 只能获取服务器返回的原始 HTML 或 JSON 数据。 无法执行 JavaScript,无法与动态内容交互。 selenium: 启动一个真实的浏览器(或无头浏览器)。 完整加载页面,包括执行 JavaScript、加载 AJAX 内容、处理动态元素。 可模拟用户操作:点击、输入、滚动、等待等。 3. 使用场景对比 场景 推荐工具 原因 爬取静态网页(HTML 源码即所需内容) ✅ requests 快速、轻量、高效 爬取动态网页(内容由...
2025-06-12
影刀考试题
第一题流程截图 Python代码段 123456789101112131415161718192021222324252627282930313233import pandas as pddf=pd.DataFrame(list1)df["票房"]=df["票房"].astype(int)df=df.groupby("制片地区")["票房"].sum().reset_index()df=df.sort_values(by="票房",ascending=False).head(3)df.insert(0,"提交人","Tetuka")res=df.values.tolist()#3.0-3.5df=pd.DataFrame(list1)df=df[(df.评分!="-")]df["评分"]=df["评分"].astype(float)df["票房"]=df[&q...
2025-07-24
亚马逊爬取
需求 打开亚马逊网址:[https://www.amazon.com/gp/bestsellers/] 根据制定的大类类目Baby/Gifts去每个小类目下统计best sellers前100名的以下指标:【分类、商品ID、标题、图片、价格、链接】 把相应信息写入数据库 把本次写入数据和上次写入数据做分析 把有新冲上来的链接、哪条链接调价的结果,发消息通知我(QQ邮箱) 表设计1234567891011CREATE TABLE amazon_items (id INT PRIMARY KEY AUTO_INCREMENT, --自增主键categories VARCHAR(64) COMMENT '分类',item_id VARCHAR(64) COMMENT '商品ID',title VARCHAR(255) COMMENT '标题',img_url VARCHAR(255) COMMENT '图片链接',price DECIMAL(8, 2) COMMENT '价格'...

2025-08-06
Python虚拟环境(conda)创建AI项目
condaConda配置完全指南-CSDN Conda 是一个开源的跨平台包管理与环境管理工具,广泛应用于数据科学、机器学习及 Python 开发领域。它不仅能帮助用户快速安装、更新和卸载第三方库,还能创建相互隔离的虚拟环境,解决不同项目之间的依赖冲突问题。例如,项目 A 依赖 Python 3.7 和 NumPy 1.0,而项目 B 需要 Python 3.10 和 NumPy 2.0,通过 conda 可分别创建独立环境,避免版本冲突。此外,conda 不仅支持 Python 包,还能管理 R、C/C++ 等非 Python 依赖,极大提升了跨语言开发的便捷性。 Anaconda 和 Miniconda Anaconda 是基于 conda 的完整发行版,预装了超过 250 个科学计算和数据分析的常用工具包(如 NumPy、Pandas、Jupyter),适合新手或需要快速搭建开发环境的用户。但 Anaconda 的安装包体积较大(约 3 GB),对存储空间有限的用户可能不够友好。 Miniconda 是 conda 的极简版本,仅包含核心的 conda 工具、P...

