亚马逊爬取
需求
- 打开亚马逊网址:[https://www.amazon.com/gp/bestsellers/]
- 根据制定的大类类目Baby/Gifts去每个小类目下统计best sellers前100名的以下指标:【分类、商品ID、标题、图片、价格、链接】
- 把相应信息写入数据库
- 把本次写入数据和上次写入数据做分析
- 把有新冲上来的链接、哪条链接调价的结果,发消息通知我(QQ邮箱)
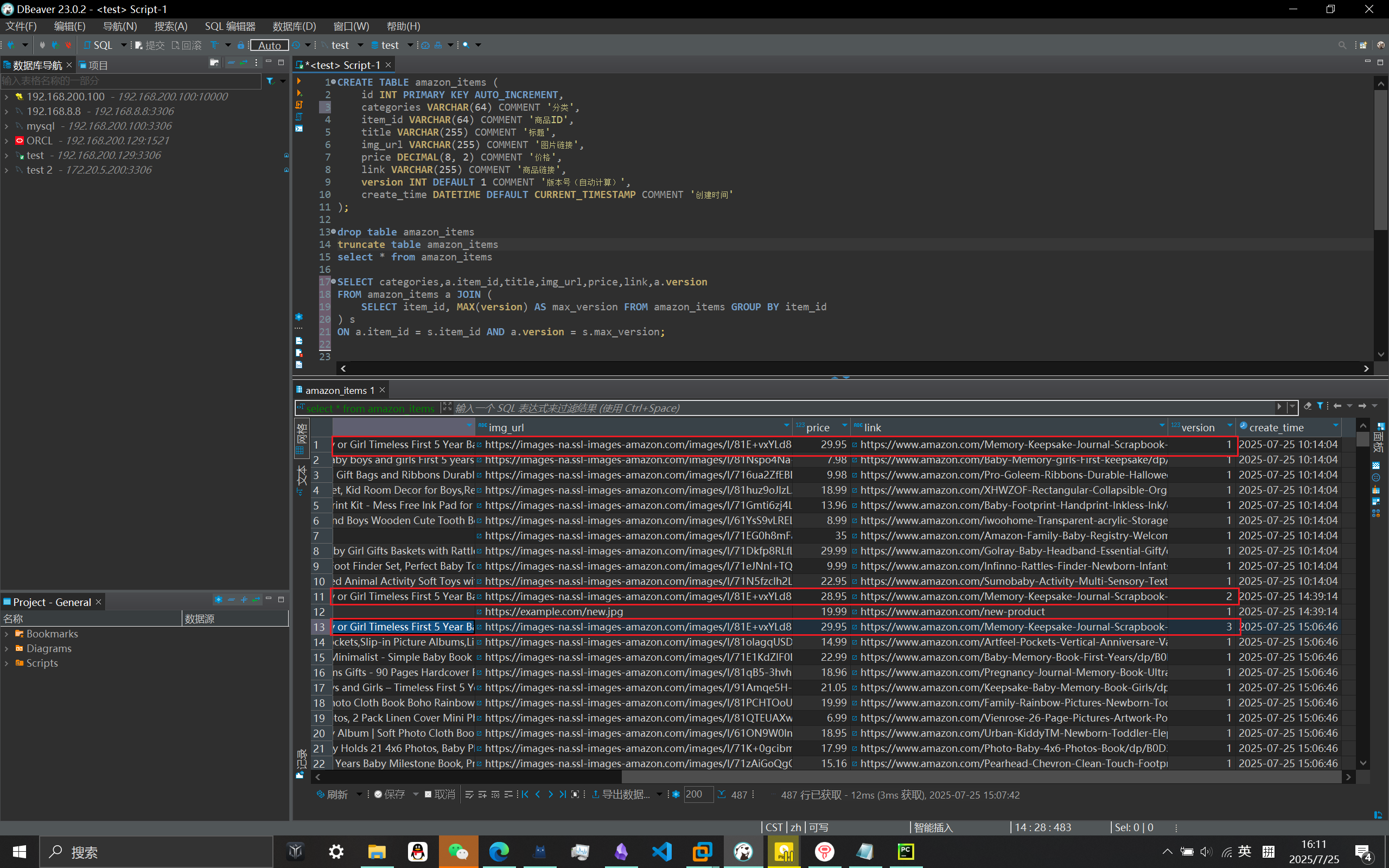
表设计
1 | CREATE TABLE amazon_items ( |
流程
主流程:打开大类网页,获取子类相似元素,ForEach循坏,获取其文本内容可取出子类标题categories(即分类),由于后面获取和存储其他商品详情在子流程中进行,使用的变量不想进行频繁传参时可将其设置为全局变量。
子流程1为爬取每页,因为只需爬取100条数据,每页为50条,因此只需点击一次下一页元素,若不足50条数据只有一页获取不到下一页元素,进行异常处理,进行下一次循环(相当于continue)
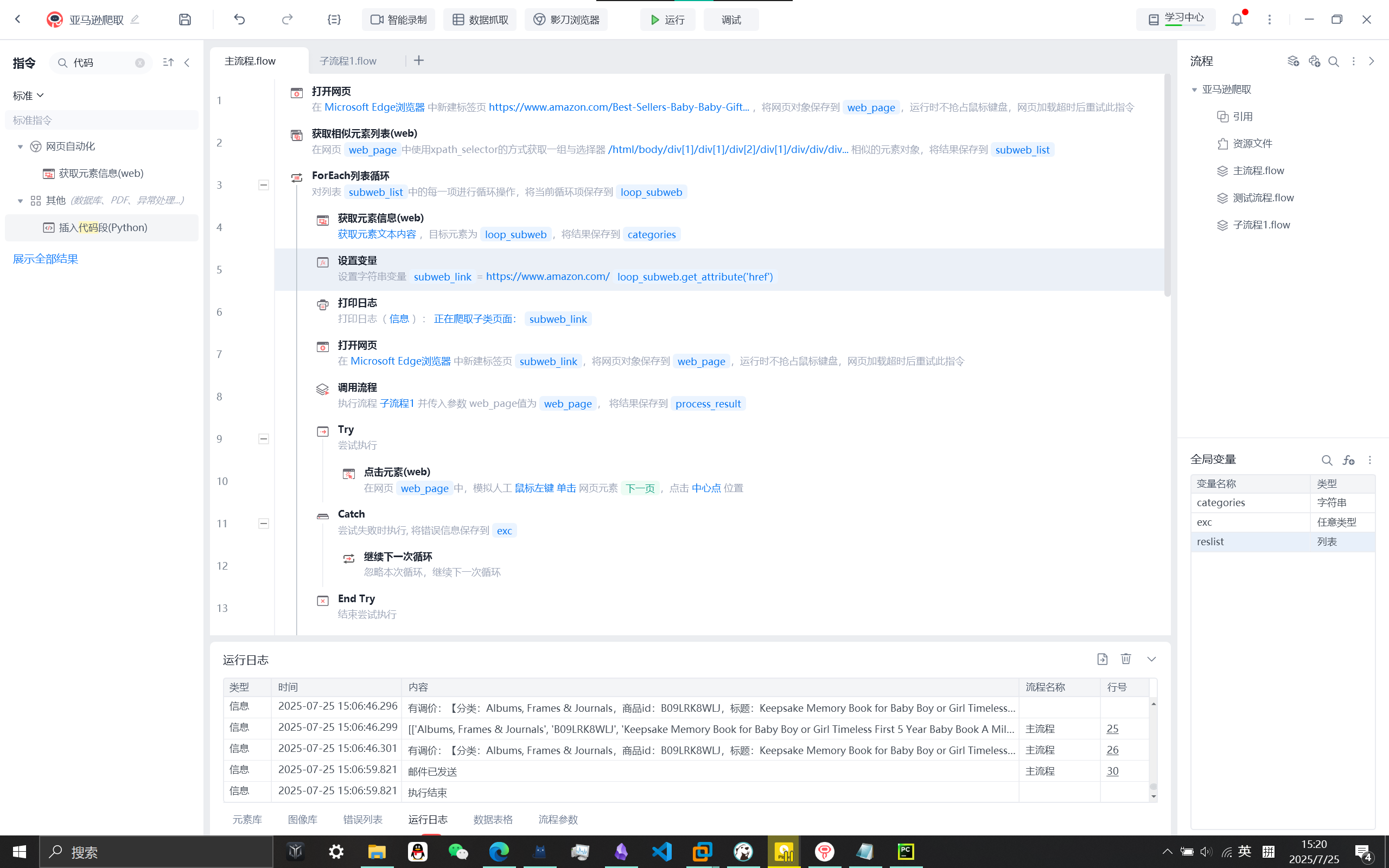
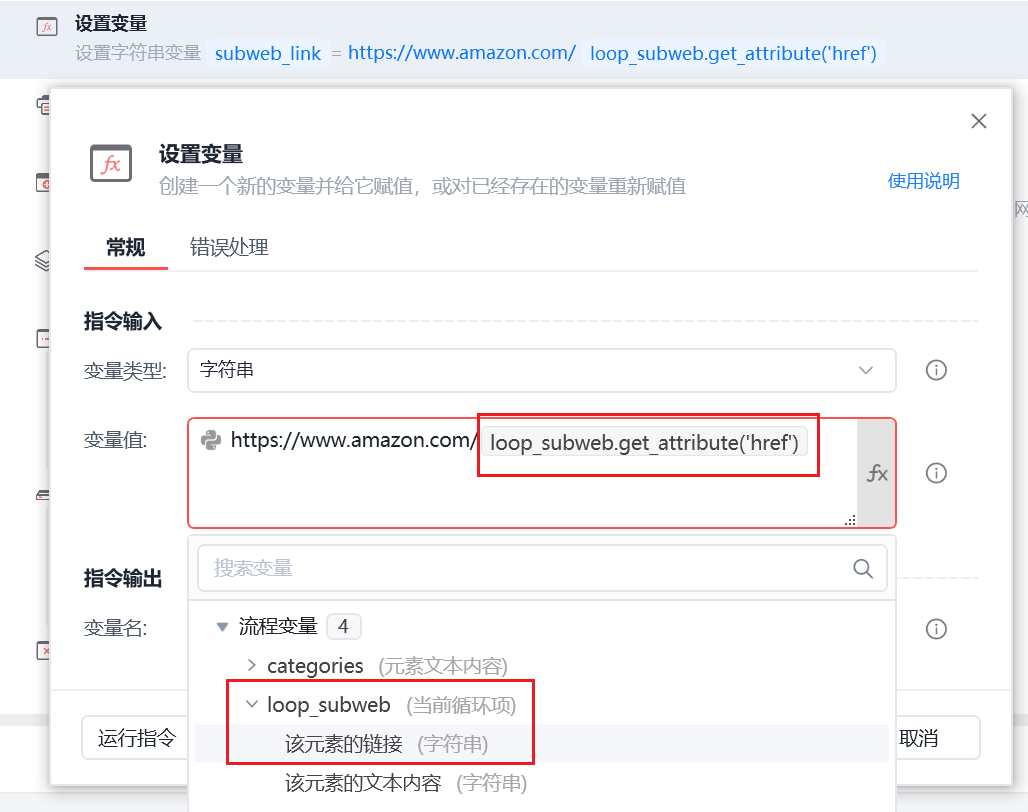
子类元素链接获取不完整,可设置变量自行拼接为一个完整链接
子流程先进行鼠标滚动加载完当页所有商品(50条),再获取相似元素循环爬取
循环的元素xpath为/html/body/div[1]/div[1]/div[2]/div[2]/div/div/div[2]/div/ol/li
若再想获取其下一层xpath元素(如:/html/body/div[1]/div[1]/div[2]/div[2]/div/div/div[2]/div/ol/li/span/div/div/div/div[2]/span/div/a)
获取对象时需勾选关联父元素,然后填写的xpath路径可为./span/div/div/div/div[2]/span/div/a其中.表示当前路径(或者说父元素路径)
可使用正则表达式从爬取的文本中提取内容,具体怎么用直接问AI就行,个人认为没必要深入了解
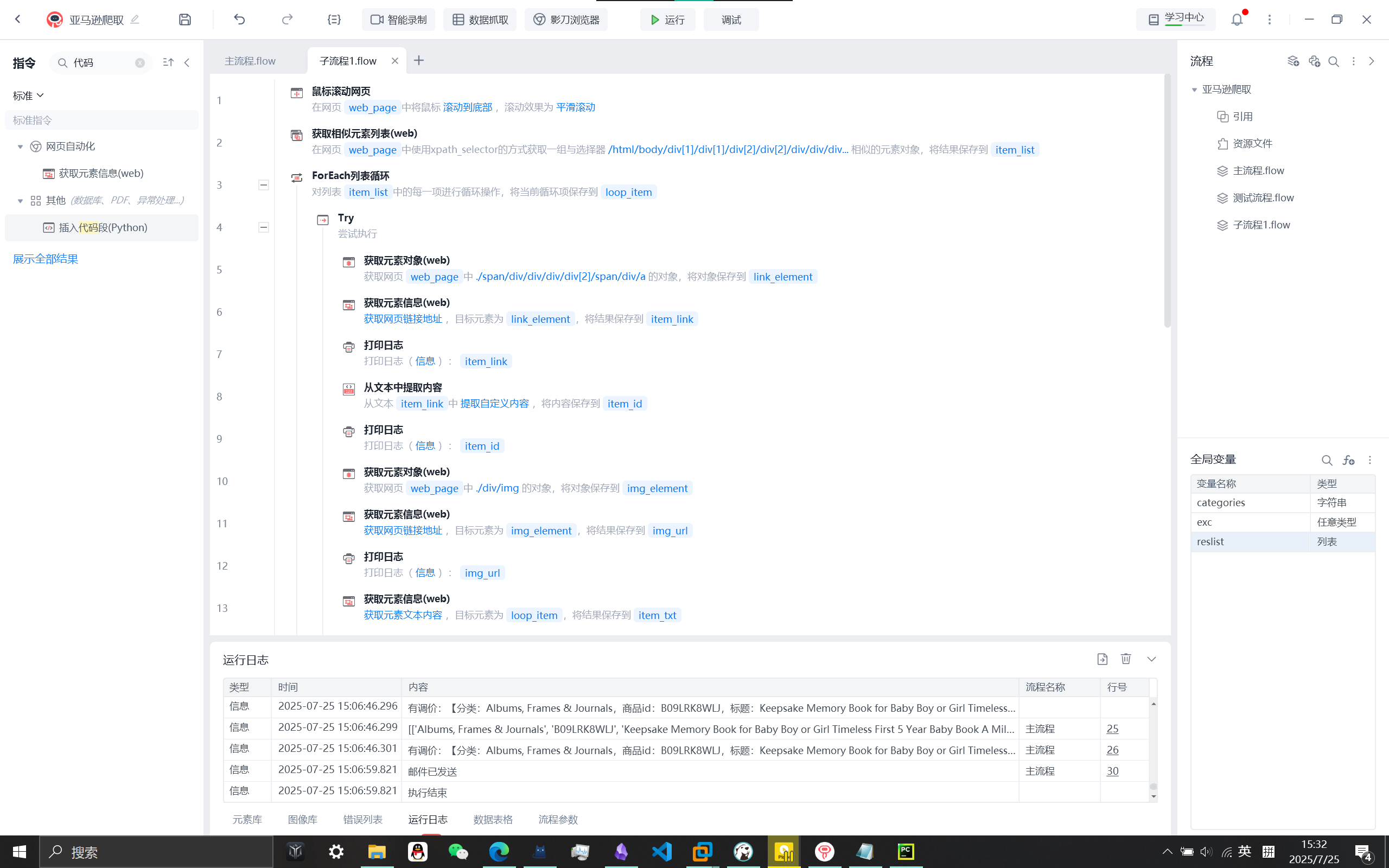
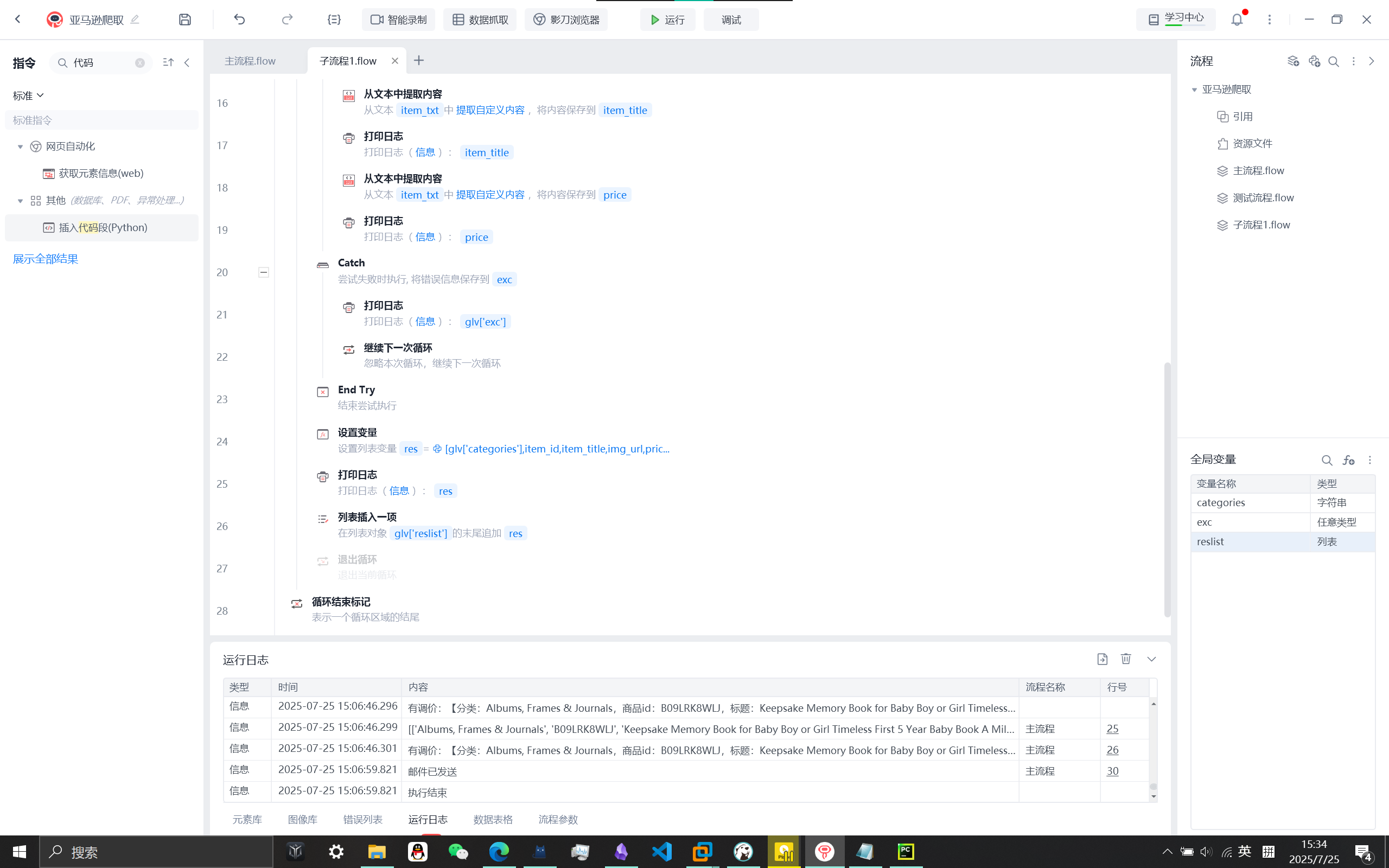
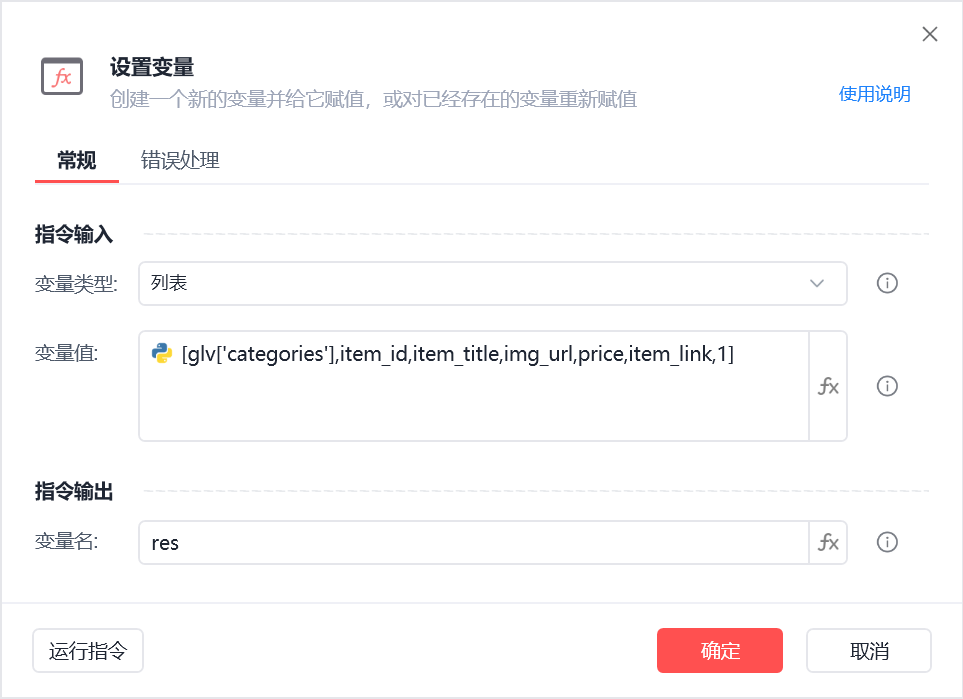
设置变量res用于存储爬到的一条数据,再添加到reslist(存储所有爬到的数据)
使用全局变量需使用glv['变量']
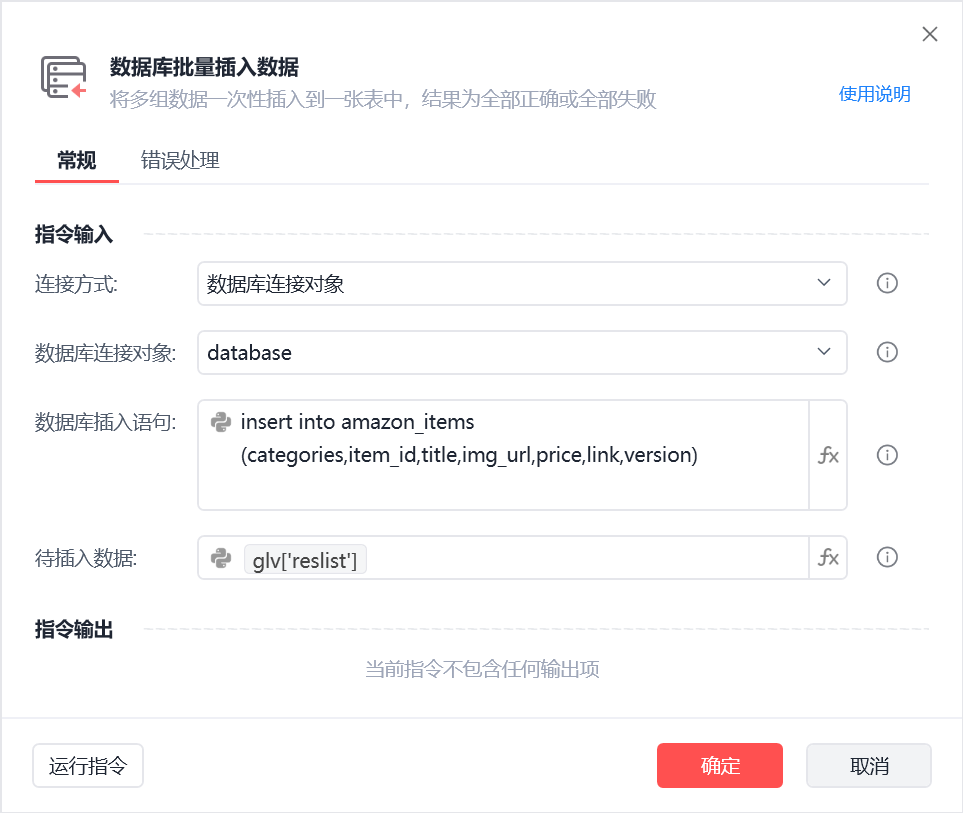
数据库批量插入数据,id和时间自动填充不用插入
主流程连接数据库,分析、插入数据,并发送邮件
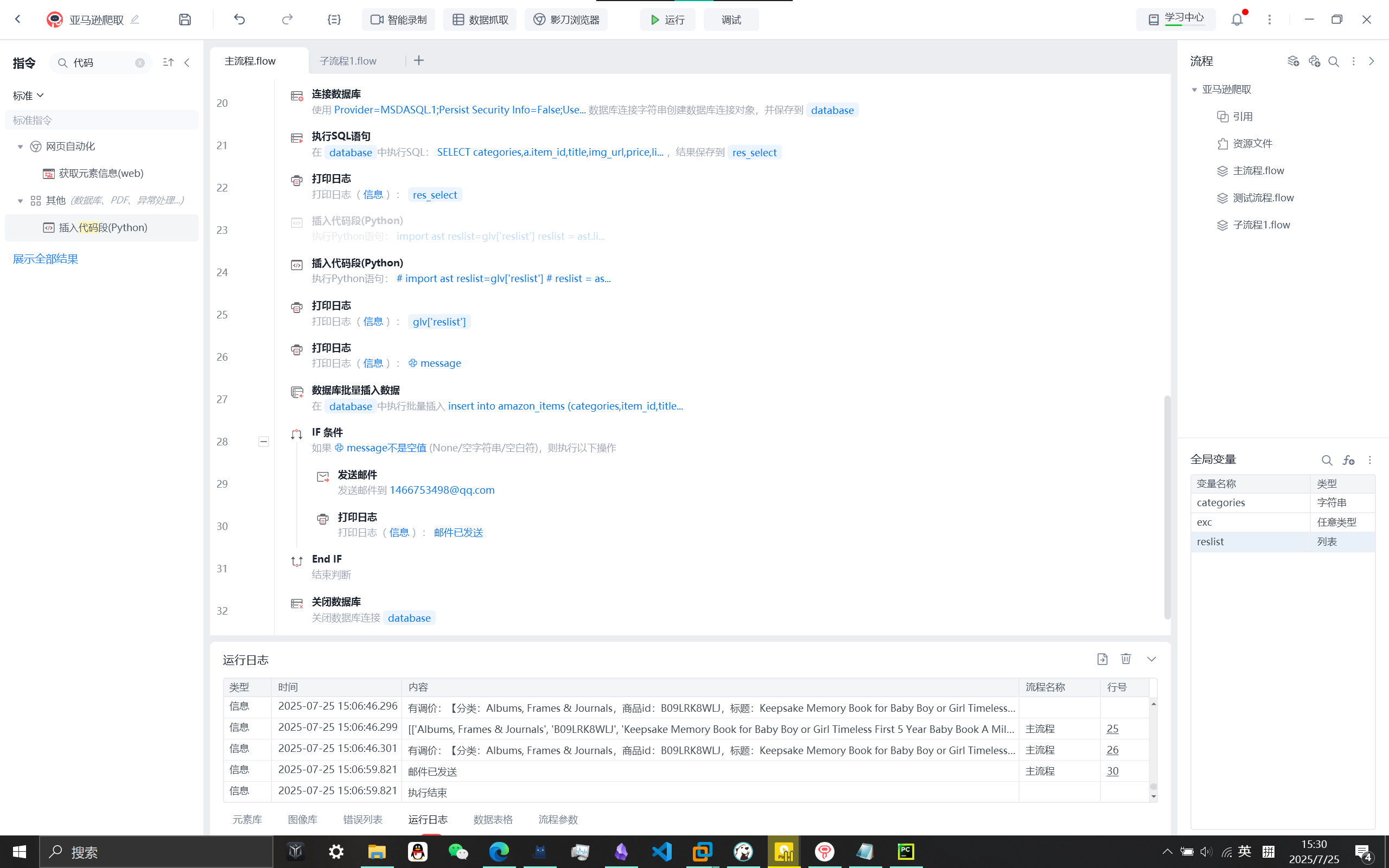
执行sql语句查询要查询每个item_id版本号最大的数据(每条商品的最新版数据)
将其保存到res_select用于与爬取的数据reslist进行上新和调价的分析
1 | SELECT categories,a.item_id,title,img_url,price,link,a.version |
插入python代码段进行爬取数据与原数据的分析:
对比relist和res_select的内容,若relist中存在res_select中没有的item_id,则在message中增加消息:有上新:【分类:categories,商品id:item_id,标题:title,价格:price,链接:link】(若有多条换行继续增加);
再对比relist和res_select相同item_id的数据,并比较price是否相同,若相同则删除relist中的该条数据(不再插入数据库),若不同,则将relist中该数据的version设置为res_select中对应的version+1,并在message中增加消息:有调价:【分类:categories,商品id:item_id,标题:title,价格:res_select.price→relist.price,链接:link】,最后打印输出message
1 | # import ast |
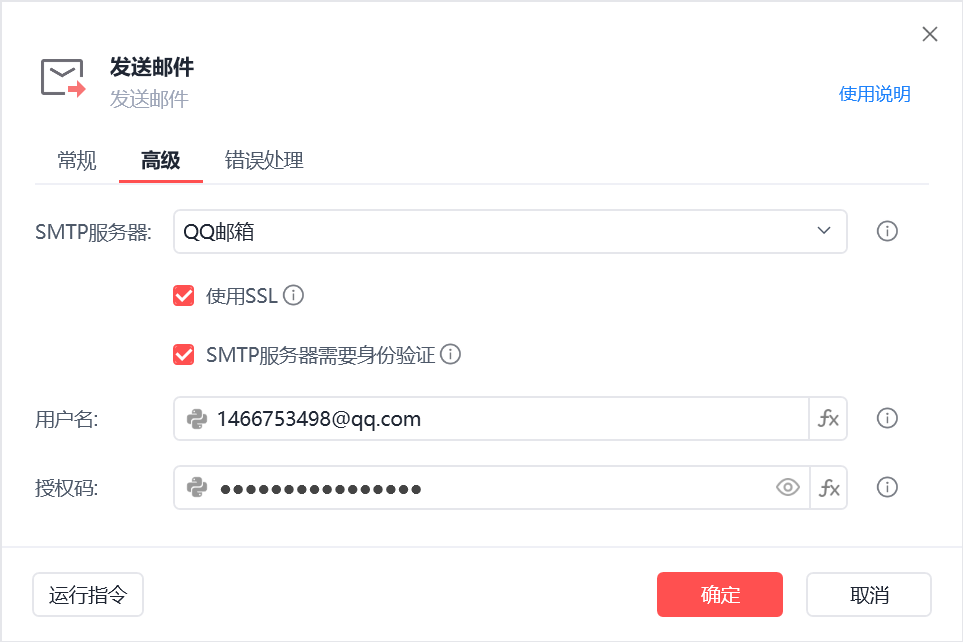
影刀RPA提供发送邮件的组件,可用于发送通知
使用QQ邮箱SMTP授权码(QQ邮箱-账号与安全-安全设置-生成授权码)
发送邮件前先判断message是否为空,为空(没有变动数据)不发送
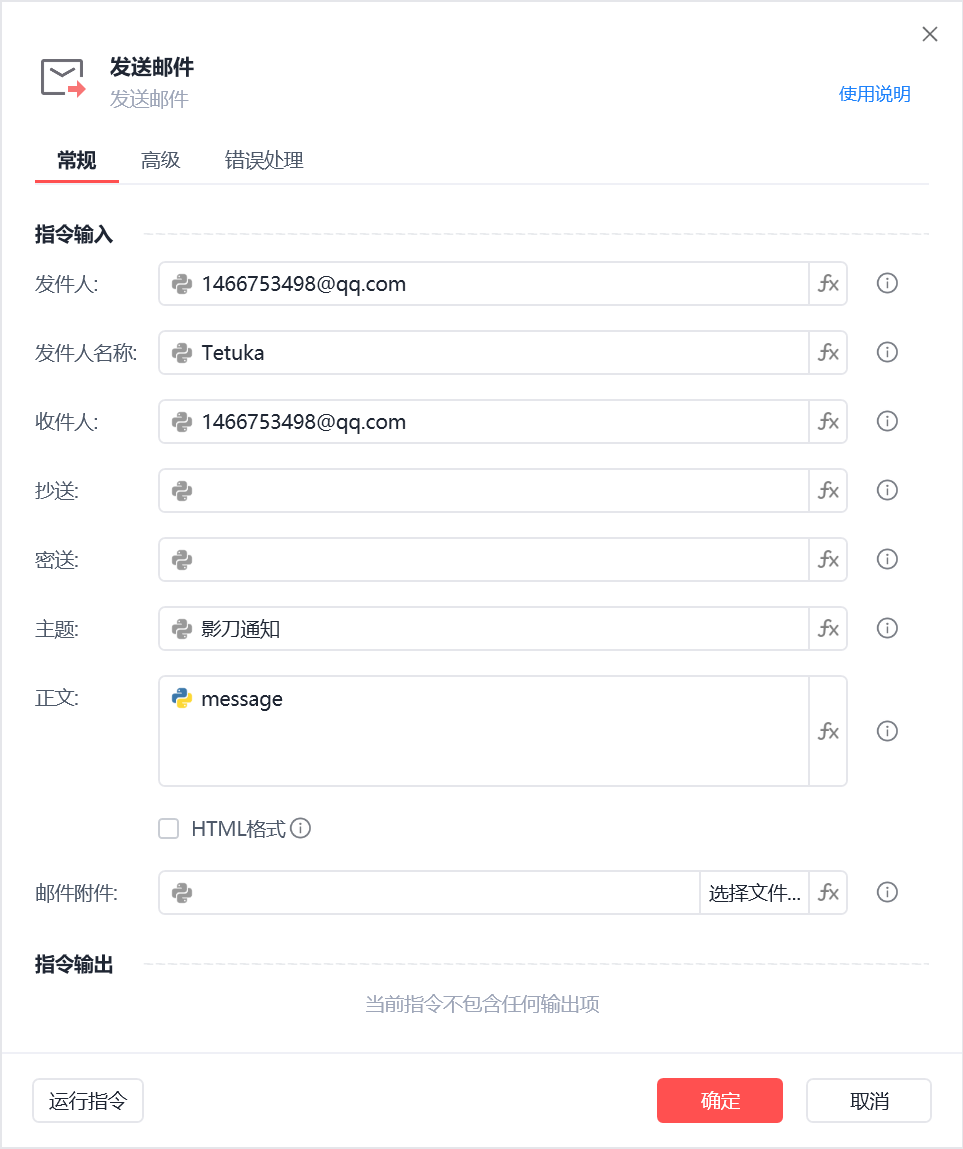
正文则使用python代码中的消息变量message(需点亮python图标)
结果验证