
影刀RPA爬取京东商品
需求
- 商品ID item_id
- 商品链接 item_link
- 标题 item_title
- 门店名称 store
- 封面 cover_link
- 原价 original_cost
- 折扣价 discount_cost
- 品牌 brand
- 型号 type
- 评论数 comments
建表
1 | CREATE TABLE IF NOT EXISTS `jd_items` ( |
流程
主流程
For次数循环点击下一页5次(实现翻页)
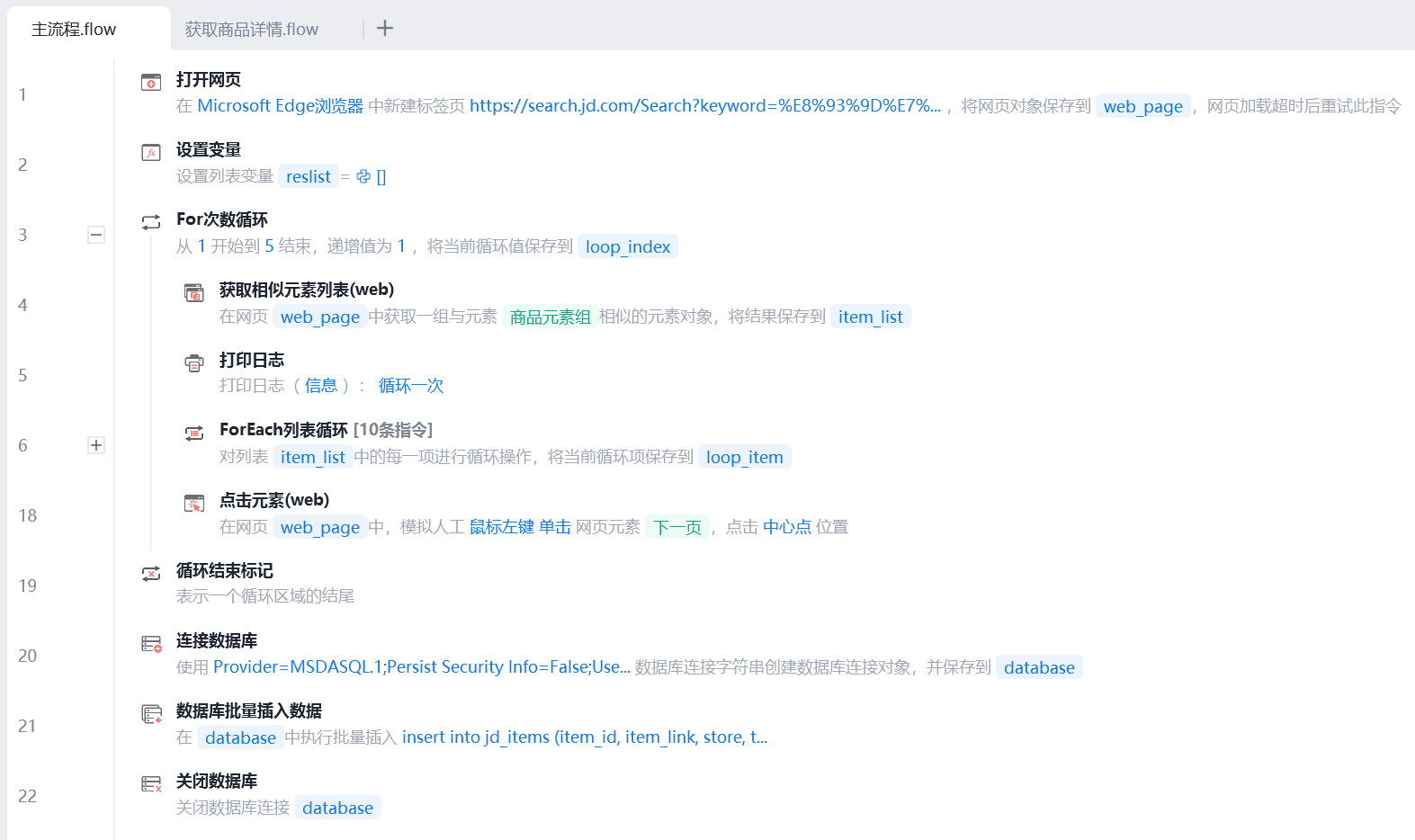
ForEach列表循环每个商品,获取详情页链接传入子流程
测试环境需要只跑一遍时可启用退出循环
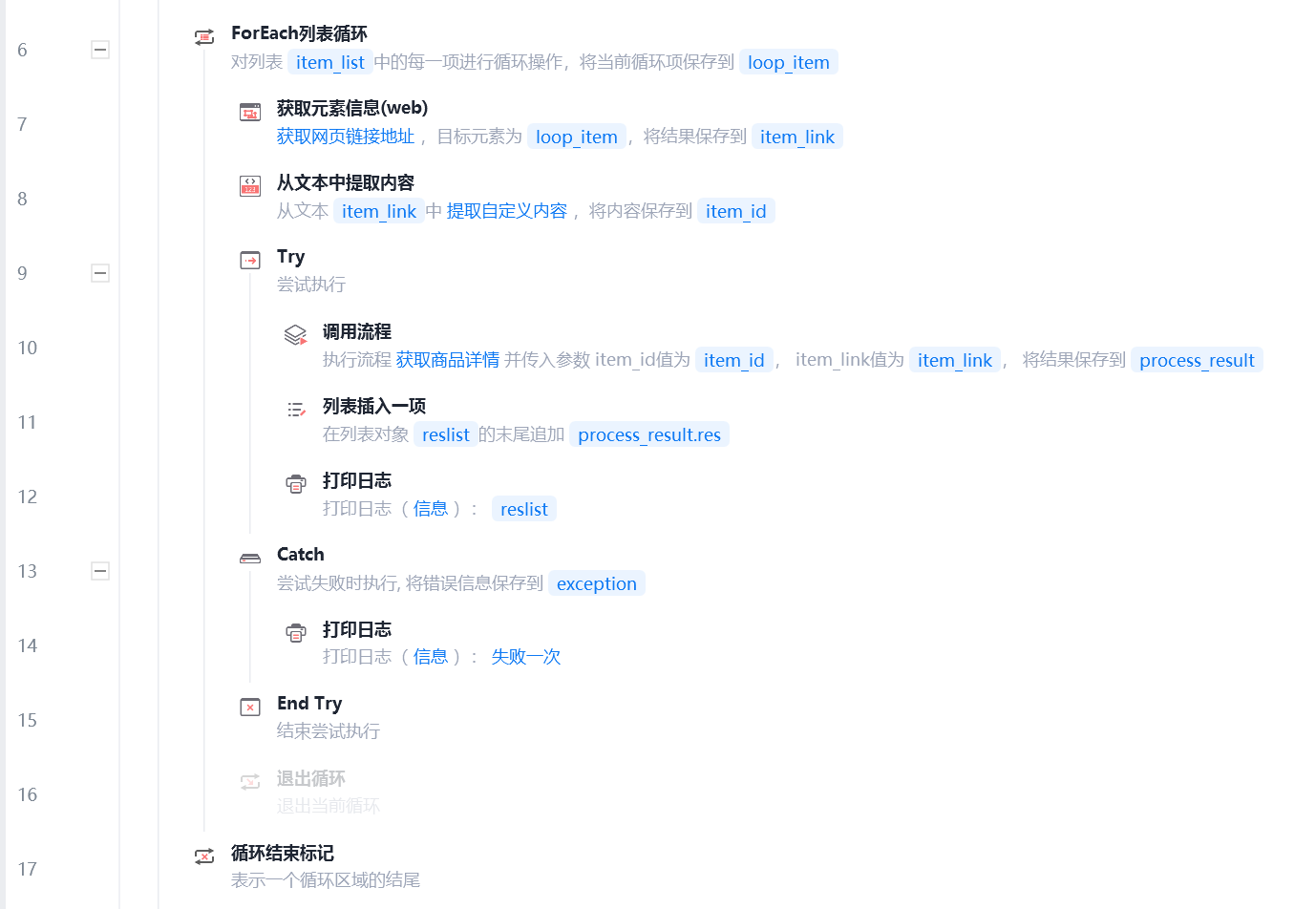
调用子流程爬取各项信息
可设置item_link默认值,可单独运行子流程对该网页进行爬取测试
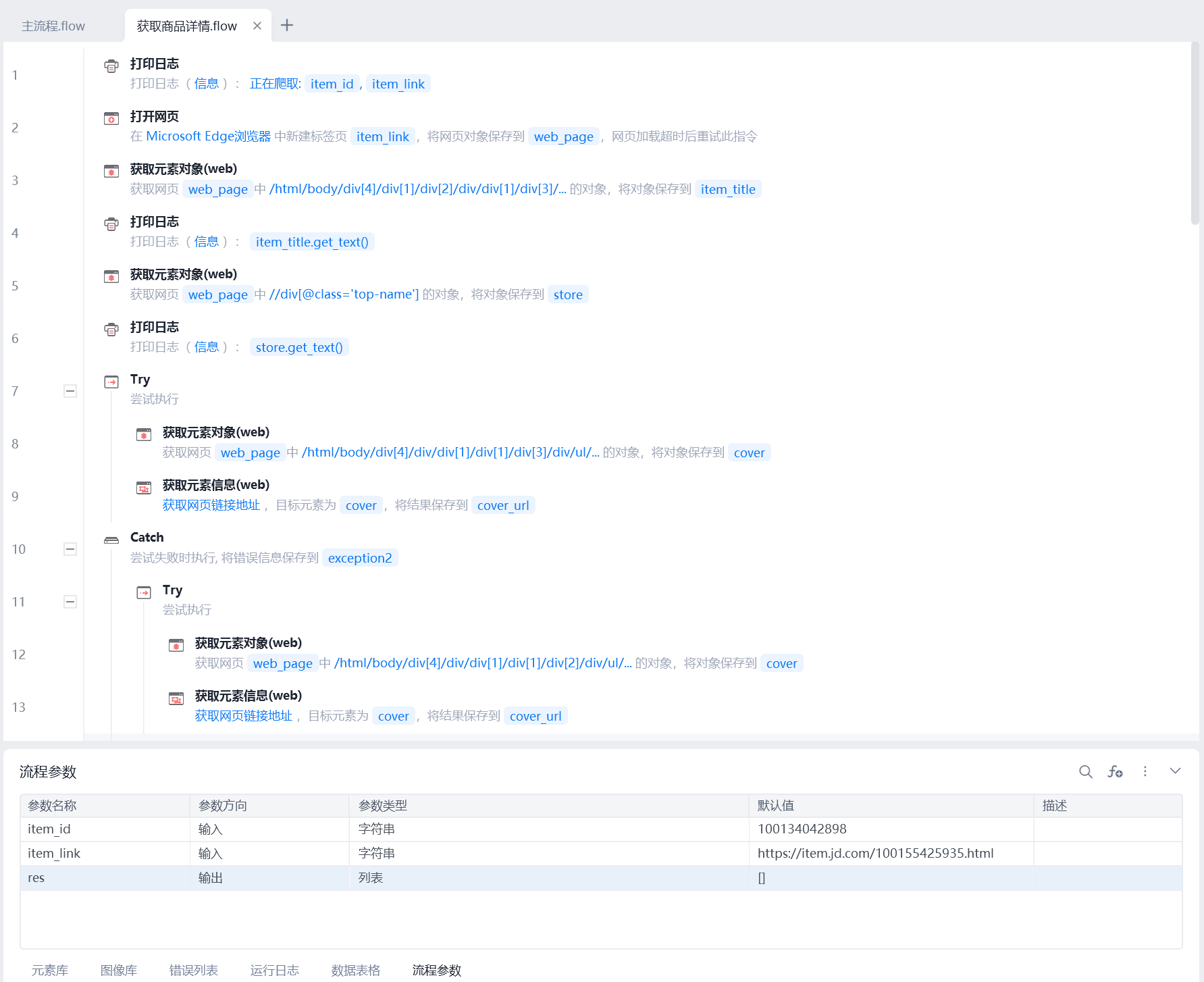
获取型号处理
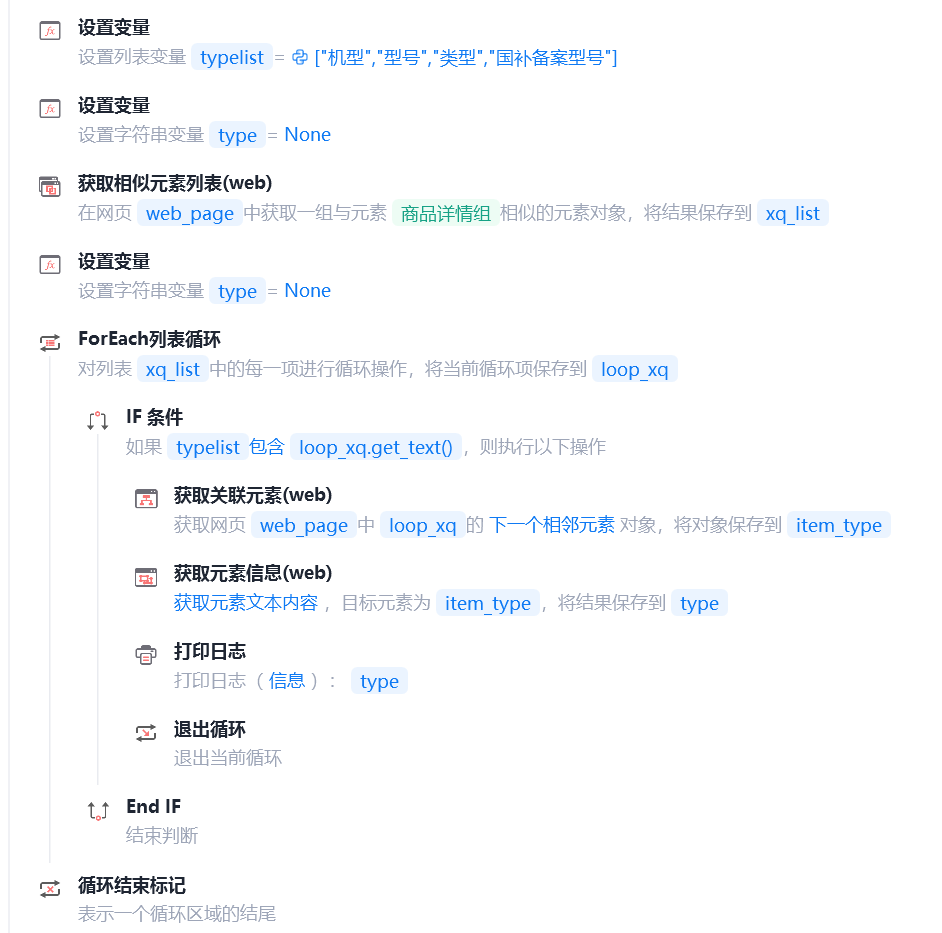
设置一个变量(列表)保存爬取的数据,输出到主流程,插入到relist(列表)作为二维列表用于批量插入数据库
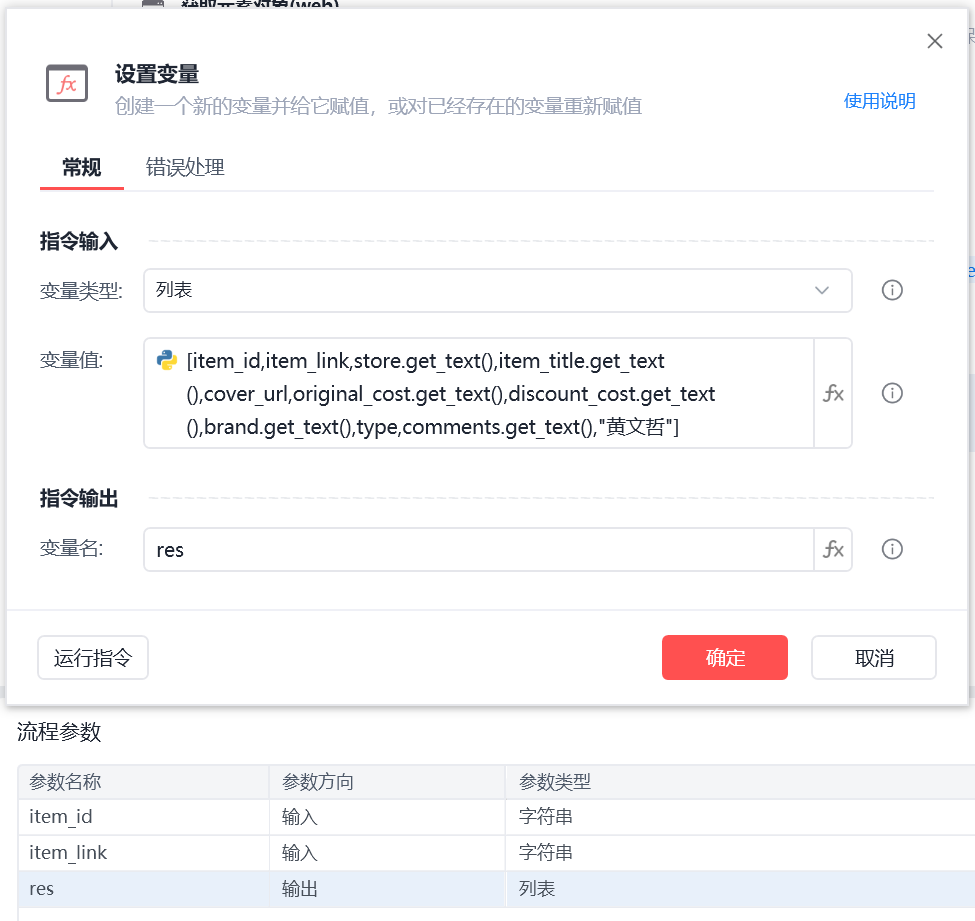
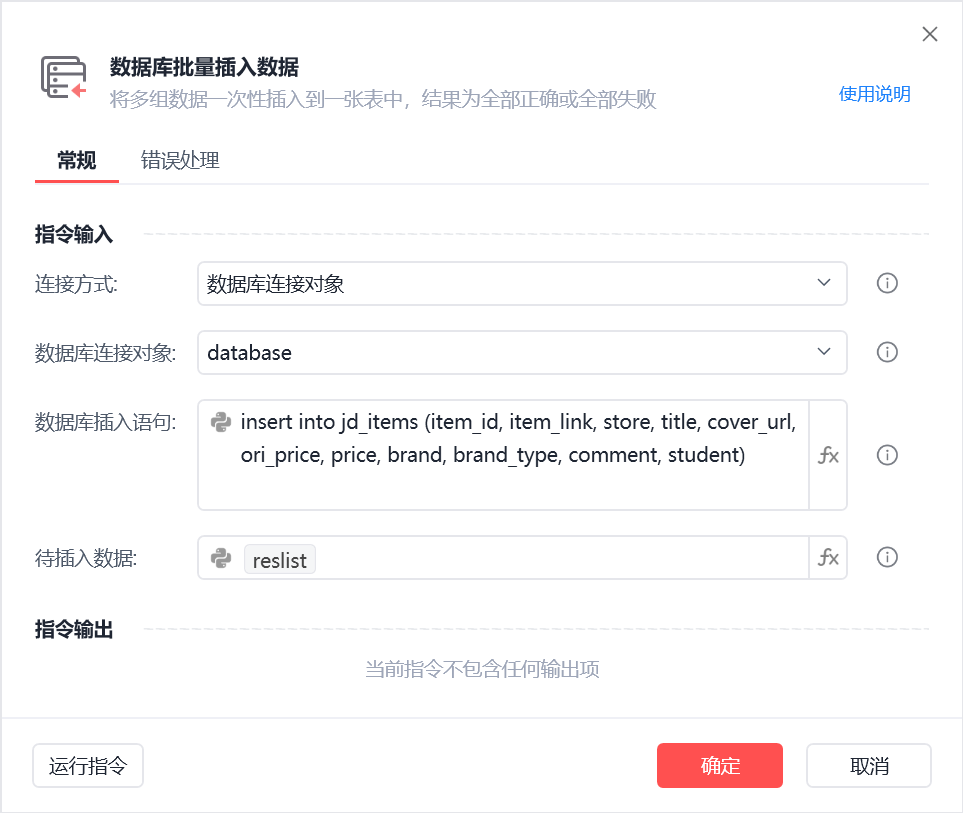
id、写入时间、更新时间为自动填充,不需要插入,因此插入语句要写列名(若完全插入则只需写表名不用写列名,但要保证插入列数与表列数一致)
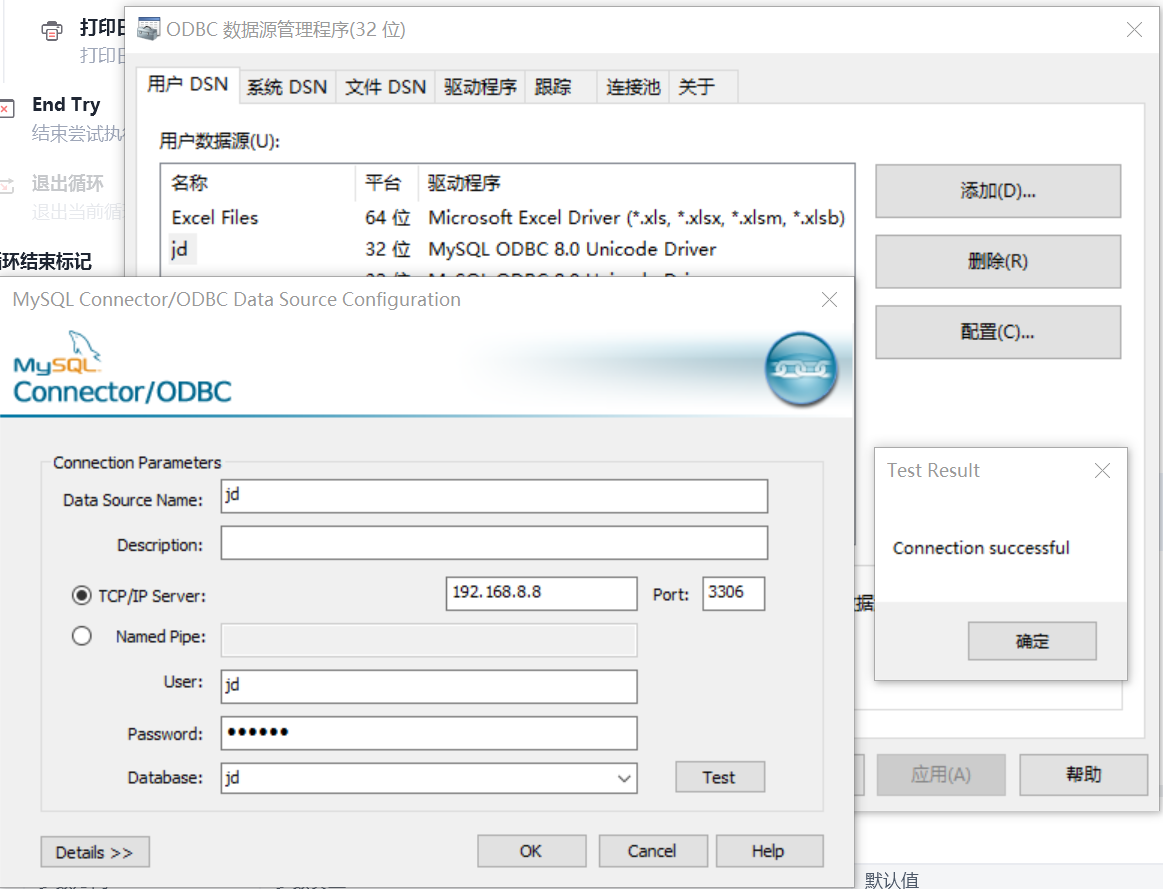
odbc程序添加数据库连接
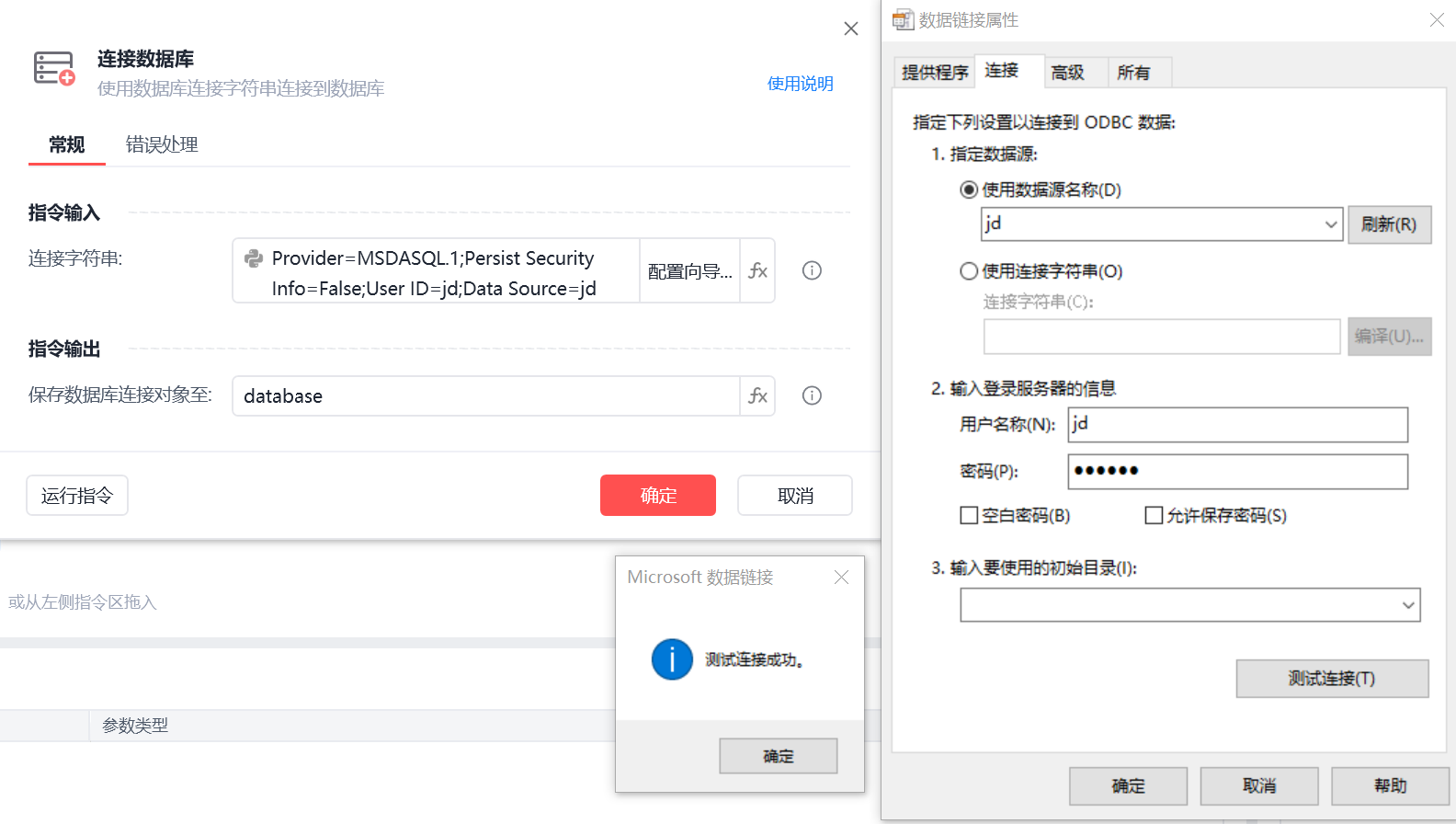
影刀连接数据库配置
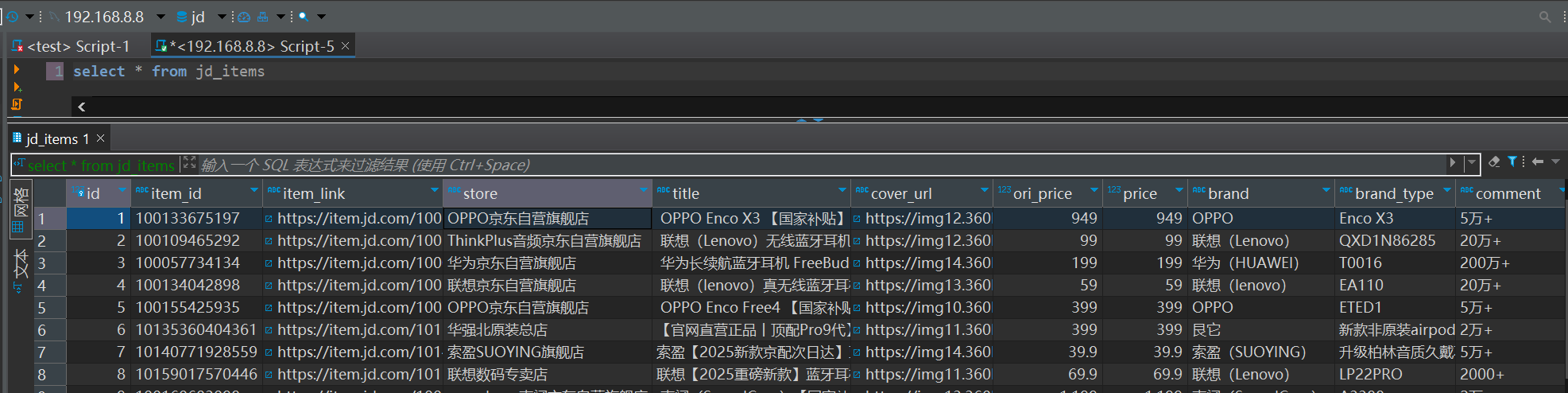
本地插入测试完成
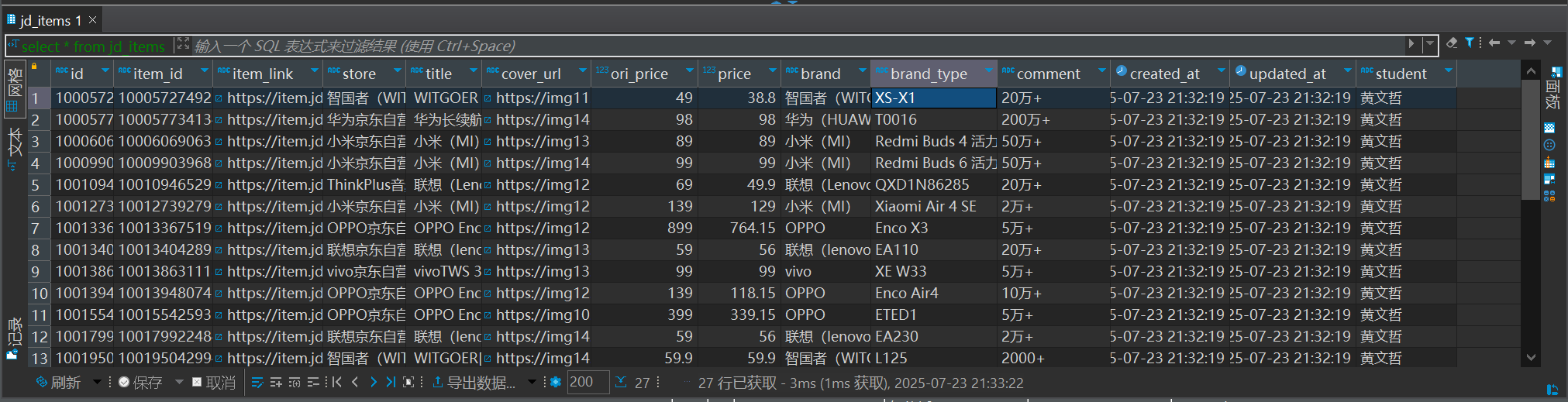
插入服务数据库完成
Xpath
XPath(XML Path Language)是一种用于在 XML 或 HTML 文档中定位和选取节点(元素、属性、文本等) 的语言。它最初为 XML 设计,由于 HTML 可以被视为 “不严格的 XML”,因此 XPath 也广泛用于 HTML 文档的解析(比如网页爬虫、数据提取等场景)。
核心用途
- 在 XML/HTML 文档中精准定位节点(如某个标签、属性或文本)。
- 从文档中提取特定数据(如网页中的标题、链接、表格内容等)。
- 作为其他技术的基础(如 XSLT 转换、XQuery 查询等)。
XPath 常与以下工具配合使用:
- Python:
lxml、Scrapy(内置 XPath 解析)、BeautifulSoup(需配合 lxml 解析器)。 - 浏览器:F12 开发者工具的 “Elements” 面板中,右键节点可直接复制 XPath。
- 其他:Java 的
Jsoup、C# 的HtmlAgilityPack等。
基本语法:节点选取规则
XPath 的语法类似文件系统的路径表示,通过 “路径表达式” 定位节点。以下是最常用的规则:
| 表达式 | 含义 | 示例 |
|---|---|---|
/ |
从根节点开始选取(绝对路径)。 | /html/body:选取根节点html下的直接子节点body。 |
// |
从任意位置选取节点(相对路径,忽略层级)。 | //a:选取文档中所有<a>标签(无论在哪个层级)。 |
. |
选取当前节点。 | ./p:选取当前节点下的直接子节点<p>。 |
.. |
选取当前节点的父节点。 | //div/..:选取所有<div>的父节点。 |
@ |
选取属性。 | //a/@href:选取所有<a>标签的href属性值(即链接地址)。 |
text() |
选取文本内容。 | //h1/text():选取所有<h1>标签内的文本。 |
[n] |
选取第 n 个节点(索引从 1 开始)。 | //li[1]:选取所有<li>中的第一个。 |
[@属性] |
按属性筛选节点。 | //a[@class]:选取所有带有class属性的<a>标签。 |
[@属性=值] |
按属性值筛选节点(值需用单 / 双引号包裹)。 | //a[@class='active']:选取class为active的<a>标签。 |
[条件] |
按条件筛选(支持逻辑运算、比较运算)。 | //book[price>30]:选取子节点price大于 30 的<book>标签。 |
示例:HTML 中提取数据
假设有一段 HTML 代码如下:
1 | <html> |
用 XPath 提取数据的示例:
- 提取
<h1>的文本://h1/text()→ 结果:Python 教程。 - 提取
<h1>的title属性://h1/@title→ 结果:主标题。 - 提取所有
<a>的链接://a/@href→ 结果:/basic、/advance。 - 提取第二个
<li>中的文本://ul/li[2]/a/text()→ 结果:高级特性。
相关推荐

2025-08-07
影刀、扣子云AI应用:简历信息提取
影刀AI Power影刀AI Power使用AI提取简历信息的简单应用 提取图片简历信息工作流 扣子(coze)主页 - 扣子API 介绍 - 文档 - 扣子 创建智能体 代码实现 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153#!/bin/python3import osfrom PyPDF2 import PdfRe...

2025-06-12
影刀考试题
第一题流程截图 Python代码段 123456789101112131415161718192021222324252627282930313233import pandas as pddf=pd.DataFrame(list1)df["票房"]=df["票房"].astype(int)df=df.groupby("制片地区")["票房"].sum().reset_index()df=df.sort_values(by="票房",ascending=False).head(3)df.insert(0,"提交人","Tetuka")res=df.values.tolist()#3.0-3.5df=pd.DataFrame(list1)df=df[(df.评分!="-")]df["评分"]=df["评分"].astype(float)df["票房"]=df[&q...

2025-09-03
RPA实现自动回复机器人
基本固定回复1.桌面自动化-获取窗口信息-窗口标题设置为“微信” 2.循环相似元素(win),捕捉微信新消息红点,捕获相似元素(另一个红点),编辑,取消acc-name的勾选(这是红点的消息数,若勾选该选项,会仅匹配捕获时的数字,当有多条消息使红点的数字变化时会匹配不到) 3.点击元素(消息红点),此时会进入聊天界面 4.填写输入框(win),捕获微信输入框元素,同样需要取消勾选acc-name,填写自动回复信息 5.点击元素(发送按钮) 6.将以上循环相似元素的循环拉入一个无限循环,使其一直执行 这样就完成了一个简单的自动回复固定消息的微信机器人,完整流程如下: 接入AI回复接入AI前需要获取聊天记录以便发送给AI让其生成回复内容 cozeAI智能体设置promopt设置: 我会发送一段消息列表,形式如下:[‘你好’, ‘【自动回复】你好啊!’, ‘你是谁’, ‘【自动回复】我是Tetuka微信聊天小助手,请问有什么需要帮助的吗?🥰’]其中包含【自动回复】的内容为你发送的消息,否则为对方用户发送的消息,请你扮演一个Tetuka微信聊天小助手,根据消息列表,回复用...
2025-07-24
亚马逊爬取
需求 打开亚马逊网址:[https://www.amazon.com/gp/bestsellers/] 根据制定的大类类目Baby/Gifts去每个小类目下统计best sellers前100名的以下指标:【分类、商品ID、标题、图片、价格、链接】 把相应信息写入数据库 把本次写入数据和上次写入数据做分析 把有新冲上来的链接、哪条链接调价的结果,发消息通知我(QQ邮箱) 表设计1234567891011CREATE TABLE amazon_items (id INT PRIMARY KEY AUTO_INCREMENT, --自增主键categories VARCHAR(64) COMMENT '分类',item_id VARCHAR(64) COMMENT '商品ID',title VARCHAR(255) COMMENT '标题',img_url VARCHAR(255) COMMENT '图片链接',price DECIMAL(8, 2) COMMENT '价格'...

2025-07-28
医药器械法规AI项目(数据爬取部分)
项目需求实现输入商品信息接口,提交商品后根据现有法律法规判断商品是否符合法律法规(暂定) 医药器械网站NMPA:医疗器械法规文件CMDE:国家药品监督管理局医疗器械技术审评中心—-法规文件药智:政策法规数据库_药智数据 NMPA数据爬取(国家药品监督管理局)首页:医疗器械法规文件实现效果:爬取以上链接每篇文章的【索引号、标题、分类、日期、文章内容、链接】并导入数据库,若有附件则将其下载至对应路径(\attachments\nmpa\索引号\文章标题\),数据库保存其附件路径及附件数。 建表1234567891011121314CREATE TABLE `hwz_nmpa` ( `id` INT NOT NULL AUTO_INCREMENT COMMENT '自增主键', `index_id` VARCHAR(50) NOT NULL COMMENT '索引号', `title` VARCHAR(200) NOT NULL COMMENT '标题', `category` VARCHAR(50) COMMENT ...

