DataX
项目地址:https://github.com/alibaba/DataX
官方文档:https://github.com/alibaba/DataX/blob/master/introduction.md
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
XXL-JOB
一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展
任务调度中心页面:http://192.168.200.100:8080/xxl-job-admin/
启停脚本:vim /opt/module/apache-hive-3.1.2-bin/bin/xxl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| #!/bin/bash
act=$1
start(){
echo "starting xxl-job"
ssh root@hadoop100 "cd /opt/module/xxljob; nohup java -jar xxl-job-admin-2.3.0.jar > xxl-job.log 2>&1 &"
ssh root@hadoop100 "cd /opt/module/xxljob; nohup java -jar xxl-job-executor-sample-springboot-2.3.0.jar > xxl-job-executor.log 2>&1 &"
ssh root@hadoop101 "cd /opt/module/xxljob; nohup java -jar xxl-job-executor-sample-springboot-2.3.0.jar > xxl-job-executor.log 2>&1 &"
ssh root@hadoop102 "cd /opt/module/xxljob; nohup java -jar xxl-job-executor-sample-springboot-2.3.0.jar > xxl-job-executor.log 2>&1 &"
}
stop(){
echo "stopping xxl-job"
ssh root@hadoop100 "ps -aux | grep xxl-job-admin | grep -v grep | awk '{print \$2}' | xargs kill -9"
ssh root@hadoop100 "ps -aux | grep xxl-job-executor-sample | grep -v grep | awk '{print \$2}' | xargs kill -9"
ssh root@hadoop101 "ps -aux | grep xxl-job-executor-sample | grep -v grep | awk '{print \$2}' | xargs kill -9"
ssh root@hadoop102 "ps -aux | grep xxl-job-executor-sample | grep -v grep | awk '{print \$2}' | xargs kill -9"
}
status(){
echo "=============== hadoop102 ================="
ssh root@hadoop102 "ps -aux | grep xxl-job-executor-sample | grep -v grep"
echo "=============== hadoop101 ================="
ssh root@hadoop101 "ps -aux | grep xxl-job-executor-sample | grep -v grep"
echo "=============== hadoop100 ================="
ssh root@hadoop100 "ps -aux | grep xxl-job | grep -v grep"
}
case $act in
start)
start
status
;;
stop)
stop
status
;;
restart)
stop
start
status
;;
status)
status
;;
esac
|
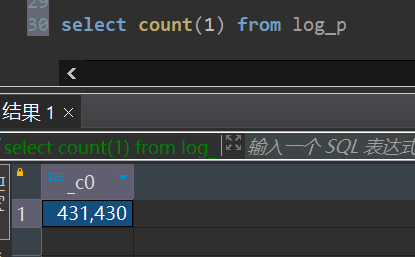
Hive 表导出到 MySQL 数据库
test_read_hdfs.json
将 HDFS 中的数据同步到 MySQL 数据库
- 从 HDFS 路径
/user/hive/warehouse/db_hive.db/sqoop_emp 读取数据
- 按制表符分隔解析文本行,提取 8 个字段
- 通过 3 个并发通道将数据传输到 MySQL
- 将数据插入到 MySQL 的
test.emp 表中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
| {
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/db_hive.db/sqoop_emp",
"defaultFS": "hdfs://hadoop100:8020",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type": "string"
},
{
"index": 5,
"type": "string"
},
{
"index": 6,
"type": "string"
},
{
"index": 7,
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "test",
"password": "test",
"column": [
"empno",
"ename",
"job",
"mgr",
"hiredate",
"sal",
"comm",
"deptno"
],
"session": [
"set session sql_mode='ANSI'"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop100:3306/test?useSSL=False&useUnicode=true&characterEncoding=utf-8",
"table": [
"emp"
]
}
]
}
}
}
]
}
}
|
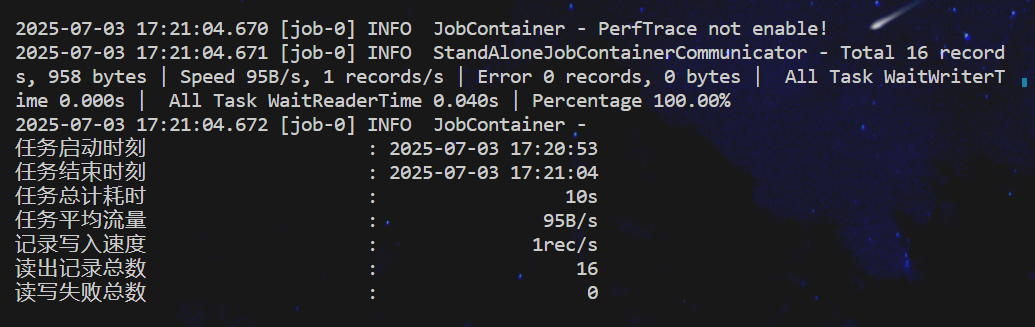
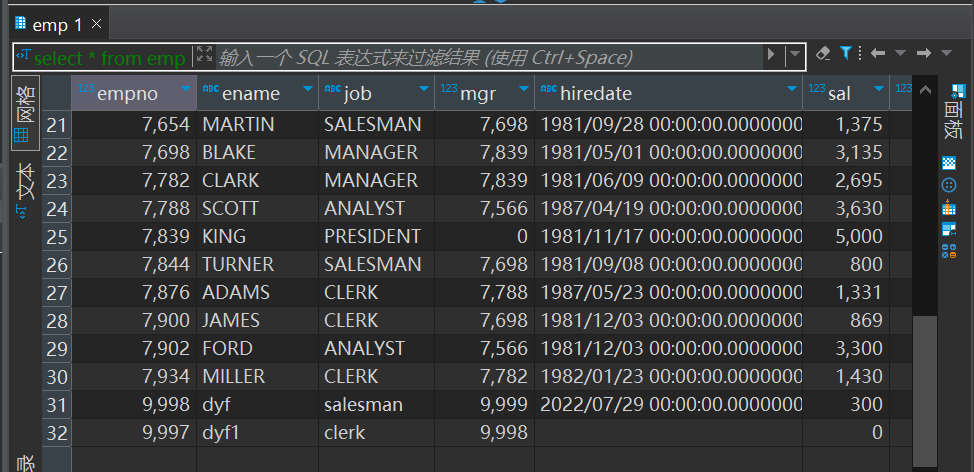
exp_log.sh
生成配置文件:根据传入的日期分区参数 $1,动态生成 DataX 配置文件 exp_log.json,配置从 HDFS 读取指定日期分区的数据,并写入 MySQL 表。
创建目标表:在 MySQL 中创建 log 表(如果不存在),定义五个 VARCHAR 类型的字段用于存储日志数据。
执行数据同步:调用 DataX 工具执行数据导出任务,将 HDFS 上的文本格式数据(/user/hive/warehouse/db_hive.db/log/dt=$part)按字段映射关系写入 MySQL 的 log 表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
| #!/bin/bash
part=$1
echo '{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/db_hive.db/log/dt='$part'",
"defaultFS": "hdfs://hadoop100:8020",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "test",
"password": "test",
"column": [
"ip",
"date_l",
"url",
"osinfo",
"bowser"
],
"session": [
"set session sql_mode='"'ANSI'"'"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop100:3306/test?useSSL=False&useUnicode=true&characterEncoding=utf-8",
"table": [
"log"
]
}
]
}
}
}
]
}
}' > /root/datax/json/exp_log.json
mysql -utest -ptest --database=test -e \
'create table if not exists log (
ip varchar(500),
date_l varchar(500),
url varchar(500),
osinfo varchar(500),
bowser varchar(500)
)'
/usr/local/bin/python3.9 /opt/module/datax/bin/datax.py /root/datax/json/exp_log.json
|
xxl-job-任务调度中心-新增任务管理
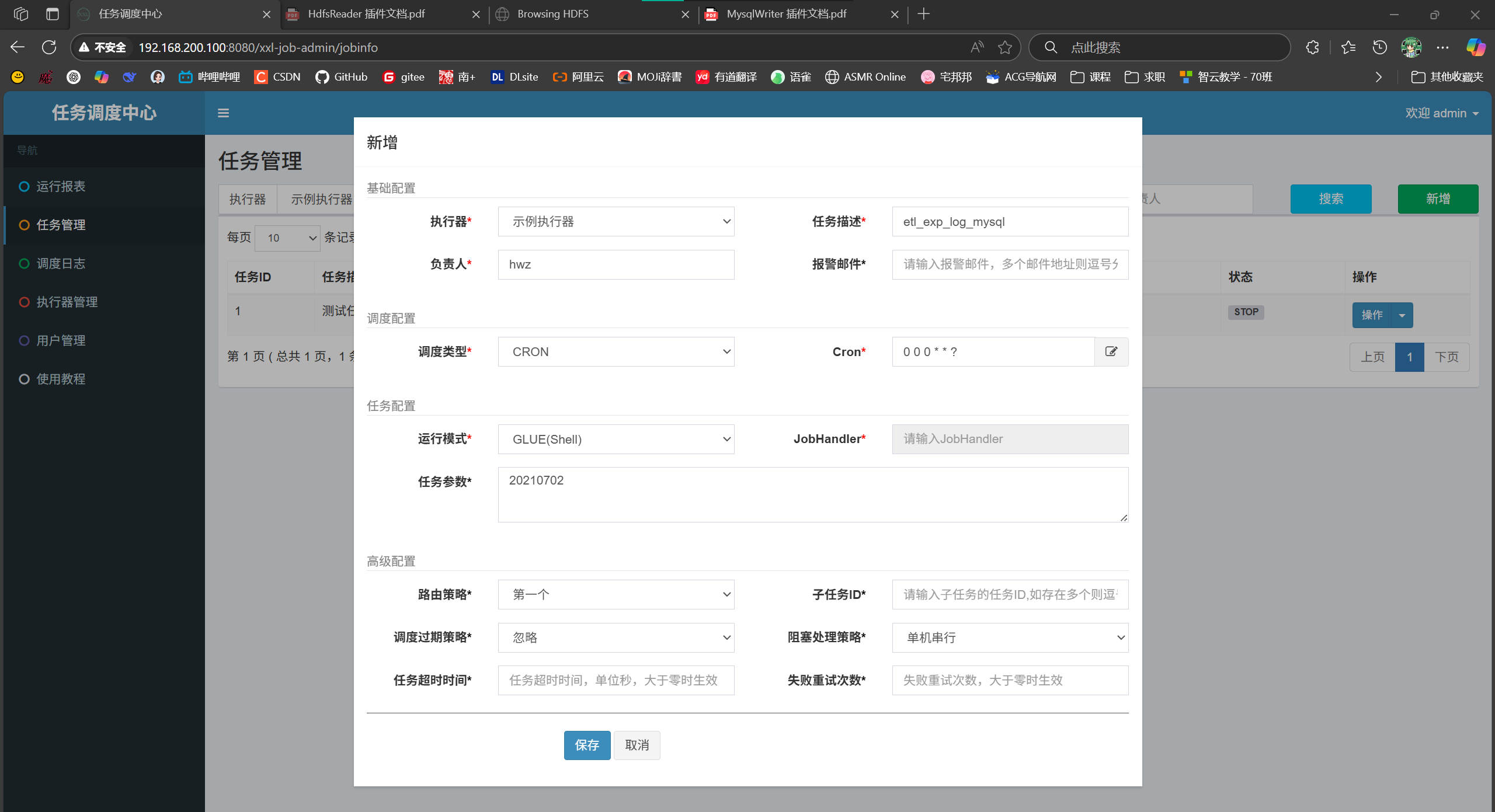
GLUE IDE
1
2
3
4
5
6
7
8
9
10
| #!/bin/bash
echo "xxl-job: hello shell"
echo "脚本位置:$0"
echo "任务参数:$1"
echo "分片序号 = $2"
echo "分片总数 = $3"
/root/datax/shell/exp_log.sh $1
echo "Good bye!"
exit 0
|
分别手动执行一次
mysql.test中查询log数据量
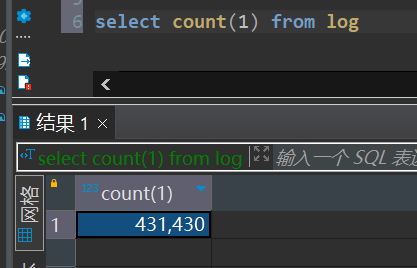
动态分区表导入导出
imp_log.json
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| {
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "test",
"password": "test",
"column": [
"*"
],
"splitPk": "db_id",
"connection": [
{
"querySql": [
"select * from log where osinfo = 'Windows';"
],
"jdbcUrl": [
"jjdbc:mysql://hadoop100:3306/test?useSSL=False&useUnicode=true&characterEncoding=utf-8"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://hadoop100:8020",
"fileType": "orc",
"path": "/user/hive/warehouse/db_hive.db/log_tmp",
"fileName": "log_p",
"column": [
{
"name": "ip",
"type": "string"
},
{
"name": "date_l",
"type": "string"
},
{
"name": "url",
"type": "string"
},
{
"name": "osinfo",
"type": "string"
},
{
"name": "browser",
"type": "string"
}
],
"writeMode": "truncate",
"fieldDelimiter": "\t",
"compress": "NONE"
}
}
}
]
}
}
|
在db_hive中建log_temp表
1
2
3
4
5
6
7
8
9
10
11
| create table log_tmp(
ip string,
date_l string,
url string,
osinfo string,
browser string
)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as orc
|
运行脚本
/usr/local/bin/python3.9 /opt/module/datax/bin/datax.py /root/datax/json/imp_log.json
imp_log.sh
- JSON 配置文件生成:创建 DataX 任务配置文件
imp_log.json,配置从 MySQL 读取数据并写入 HDFS 的 ORC 文件格式。
- Hive 表创建:使用 Beeline 连接 Hive,创建两个 ORC 格式的表:
log_tmp:临时表,用于存储从 MySQL 导入的原始数据log_p:分区表,按操作系统类型 (os_tp) 分区
- 数据抽取与导入:调用 DataX 工具执行数据同步任务,将 MySQL 的
log 表数据导入到 Hive 的 log_tmp 表。
- 动态分区插入:配置 Hive 动态分区参数,将
log_tmp 表的数据按 osinfo 字段的值自动分配到 log_tmp2 表的不同分区中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
| #!/bin/bash
echo '
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "test",
"password": "test",
"column": [
"*"
],
//"splitPk": "db_id",
"connection": [
{
"table": [
"log;"
],
"jdbcUrl": [
"jdbc:mysql://hadoop100:3306/test?useSSL=False&useUnicode=true&characterEncoding=utf-8"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://hadoop100:8020",
"fileType": "orc",
"path": "/user/hive/warehouse/db_hive.db/log_tmp",
"fileName": "log_tmp",
"column": [
{
"name": "ip",
"type": "string"
},
{
"name": "date_l",
"type": "string"
},
{
"name": "url",
"type": "string"
},
{
"name": "osinfo",
"type": "string"
},
{
"name": "browser",
"type": "string"
}
],
"writeMode": "truncate",
"fieldDelimiter": "\t",
"compress": "NONE"
}
}
}
]
}
}' > /root/datax/json/imp_log.json
beeline -u jdbc:hive2://hadoop100:10000/db_hive -u root -p 545456 -e \
"CREATE TABLE if not exists log_tmp(
ip string,
date_l string,
url string,
osinfo string,
browser string
)
row format delimited
fields terminated by '\t'
lines TERMINATED by '\n'
STORED AS orc;
CREATE TABLE if not exists log_p(
ip string,
date_l string,
url string,
osinfo string,
browser string
)
partitioned by (os_tp string)
row format delimited
fields terminated by '\t'
lines TERMINATED by '\n'
STORED AS orc "
echo '*******************建表完成--***********************'
/bin/python3 /opt/module/datax/bin/datax.py /root/datax/json/imp_log.json
echo '*****************数据导入成功************************'
beeline -u jdbc:hive2://hadoop100:10000/db_hive -u root -p 545456 -e \
"
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=200;
set hive.exec.max.dynamic.partitions.pernode=50;
set hive.exec.max.created.files=1000;
set hive.error.on.empty.partition=false;
set hive.support.quoted.identifiers=none;
insert into log_p partition (os_tp) select l.*,osinfo from log_tmp l;
"
echo '------------------完成------------------'
|