
Hive分区表、分桶表
分区表
分区是将一个表或索引物理地分解为多个更小、更可管理的部分。
分区对应用透明,即对访问数据库的应用而言,逻辑上讲只有一个表或一个索引(相当于应用“看到”的只是一个表或索引),但在物理上这个表或索引可能由数十个物理分区组成。
在 Hadoop 中,Hive 分区表通常以特定的目录结构来存储。
每个分区对应一个独立的目录,目录名通常包含分区列的值。数据文件会存储在相应的分区目录下。
分桶表
•分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。
•分桶是将数据集分解成更容易管理的若干部分的另一个技术。
•分区针对的是数据的存储路径;分桶针对的是数据文件。
分桶策略:Hive的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方 式决定该条记录存放在哪个桶当中。
| 分区表 | 分桶表 | |
|---|---|---|
| 划分依据 | 分区列的离散值(目录分割) | 分桶列的哈希值(文件分割) |
| 数量灵活性 | 分区数量可动态新增 | 桶数量固定(创建时指定) |
| 优化目标 | 减少扫描范围(过滤查询) | 优化 Join 和抽样(哈希分片) |
实践练习
1.清洗excel文件 超市数据.xlsx 为文本文件,按照分区字段对文件进行拆分
ps: 浮点数精确小数点后2位,不需要有表头和index ,数据分隔符不能是逗号
数据清洗脚本:
1 | import pandas as pd |
2.创建一个分区表,做分桶 clustered by (id ) into 2 buckets, 将文本文件分别 插入到分区中
1 | create table supermarket_p1 ( |
上传数据到hdfs系统
1 | hdfs dfs -mkdir -p /user/hive/warehouse/supermarket/data |
插入数据
1 | load data inpath '/user/hive/warehouse/supermarket/data/办公用品.txt' |
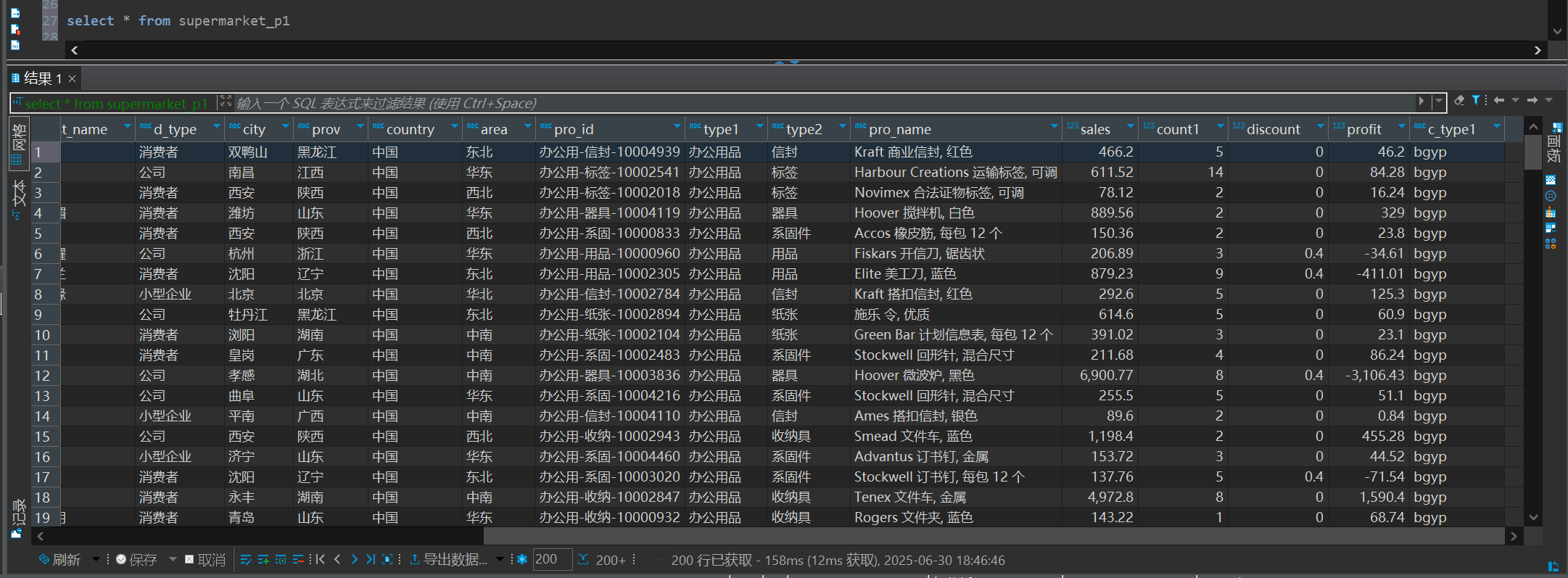
3.创建一个 按订单时间分区的分区表 (year_ string, month_ string)
1 | create table supermarket_p2 ( |
动态分区配置
1 | --开启动态分区(默认开启) |
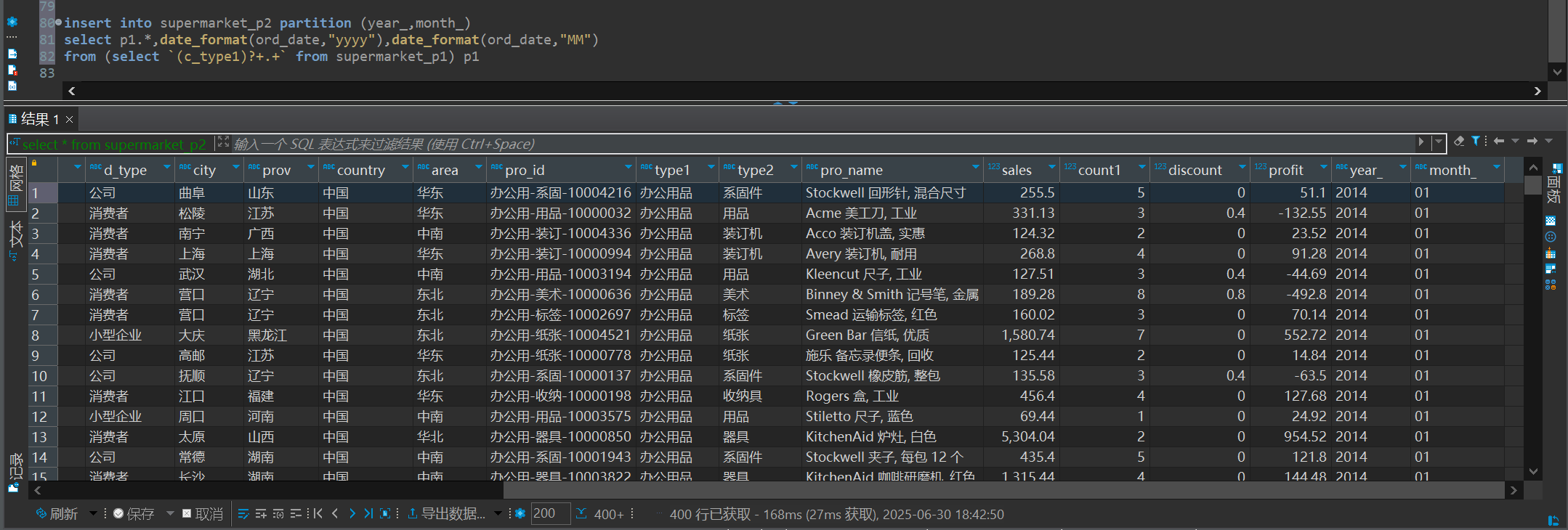
4.将第二部的数据 使用动态分区的方法 导入到 第三步的表中
1 | insert into supermarket_p2 partition (year_,month_) |
相关推荐

2025-06-24
6.24 Hadoop部署
Hadoop简介 Hadoop是一个由Apache基金会所开发的分布式系统基础架构 主要解决,海量数据的存储和海量数据的分析计算问题 广义上来说,Hadoop通常是指一个更广泛的概念-Hadoop生态圈 分布式存储Hadoop 的分布式存储主要基于 HDFS(分布式文件系统):HDFS将数据分割成多个数据块(block),这些数据块分散存储在集群中的不同节点上。每个数据块会有多个副本,通常默认是 3 个副本.采用分布式存储在不同的节点上,提高了数据的可靠性和容错性。 Hadoop的分布式核心组件是MapReduce编程模型:在MapReduce任务中,数据被切分为多个任务,每个任务由或多个节点并行。每个节点负责将输入数据映射为键-值对生成中间结果。最后,中间结果按照键的排序进行合并和归并。 Hadoop组件HDFSHDFS组件用于存储数据,主要由NameNode,DataNode,SecondaryNameNode 组成 NameNode (nn): 存储文件的元数据,如文件名,文件目录结构,文件属性 (生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNo...

2025-06-27
Hive复合数据类型、相关函数
Hive复合数据类型通过以下三种复合类型,Hive 能够高效处理半结构化数据(如日志、JSON),避免频繁进行表连接操作 array 数组array<value数据类型>存储同类型元素的有序集合,元素通过索引访问(从 0 开始) 12345--查询复合数据select a_score[0] from student2--构造复合数据-arrayselect array(值,值) from student struct 集合struct<key值:value数据类型,key值:value数据类型>存储不同类型字段的集合,每个字段有名称和类型,通过点号(.)访问 12345--查询复合数据select s_score.chinese from student2--构造复合数据select named_struct(key,value,key,value) from student map 字典map<key数据类型,value数据类型>存储键值对(Key-Value)集合,键必须唯一,通过键访问值 12345--查询复合数据select m_...

2025-07-07
hadoop问答
1. hadoop组件有哪些?分别有什么功能 组件 功能 HDFS 分布式文件存储系统,提供高容错性海量存储 MapReduce 分布式计算框架,并行处理大数据集 YARN 资源调度系统,管理集群资源并分配任务 Hive 主要用于处理结构化和半结构化数据 Common 通用工具库,支持其他模块 2. 分布式存储的组件是什么 ?有哪些进程? 进程的作用是什么?分布式存储组件是 HDFS,其包含的进程及作用如下: 进程 作用 NameNode 管理元数据(文件名、块位置、权限),响应客户端请求 DataNode 存储实际数据块,定期向NN发送心跳和块报告 SecondaryNameNode 定期合并FsImage和Edits日志(非热备,缓解NN压力) 3. 资源调度使用什么组件? 该组件有哪些进程?每个进程的作用是什么?资源调度使用的组件是 YARN,相关进程及作用如下: 进程 作用 ResourceManager 负责全局资源的调度和分配 NodeManager 管理单个节点上的资源和容器 Applicat...
2025-08-04
医药项目:数据清洗、合并
SparkSQLSpark SQL 是 Apache Spark 生态系统中的一个核心模块,专门用于处理结构化数据。它为用户提供了使用 SQL 语句或 DataFrame API 来查询和操作数据的能力,极大地简化了大数据分析任务的开发流程。 一、Spark SQL 的核心特点 统一的数据访问方式Spark SQL 支持从多种数据源读取数据,包括: JSON、Parquet、ORC、CSV 等文件格式 JDBC/ODBC 接口连接传统数据库(如 MySQL、PostgreSQL) Hive 表(通过 HiveContext) Kafka 流数据(结合 Structured Streaming) SQL 支持用户可以直接使用标准 SQL 查询数据,例如: 1SELECT name, age FROM people WHERE age > 30 这使得熟悉 SQL 的数据分析师可以轻松上手。 DataFrame 和 Dataset APISpark SQL 提供了高层次的抽象: DataFrame:以结构化方式组织的分布式数据集,类似于传统数据库中的表或 P...

2025-06-25
6.25 Hive安装、配置beeline
安装mysql12345678910111213141516#下载安装源wget https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm# 安装 mysql 源yum localinstall mysql57-community-release-el7-11.noarch.rpm# 导入keyrpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022# 修改国内源vim /etc/yum.repos.d/mysql-community.repo修改 baseurl 为 https://mirrors.cloud.tencent.com/mysql/yum/mysql-5.7-community-el7-x86_64/#安装mysqlyum install -y mysql-community-server 安装Hive12345678910111213#解压apache-hive-3.1.2-bin.tar.gz到/opt/module/...

2025-06-26
Python连接Hive
hadoop上传数据12345hadoop dfs -mkdir /emphadoop dfs -put emp0901.txt /emp/hadoop dfs -mkdir /studenthadoop dfs -put student2.csv /student/ 处理student2.txt表12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849import jsondef transform_student_data(input_file, output_file): """ 将JSON格式的学生数据转换为CSV格式 参数: input_file: 输入JSON数据文件路径 output_file: 输出CSV文件路径 """ try: with open(input_file, 'r', encoding=&#x...