6.24 Hadoop部署
Hadoop简介
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构
- 主要解决,海量数据的存储和海量数据的分析计算问题
- 广义上来说,Hadoop通常是指一个更广泛的概念-Hadoop生态圈
分布式存储
Hadoop 的分布式存储主要基于 HDFS(分布式文件系统):
HDFS将数据分割成多个数据块(block),这些数据块分散存储在集群中的不同节点上。每个数据块会有多个副本,通常默认是 3 个副本.采用分布式存储在不同的节点上,提高了数据的可靠性和容错性。
Hadoop的分布式核心组件是MapReduce编程模型:
在MapReduce任务中,数据被切分为多个任务,每个任务由或多个节点并行。每个节点负责将输入数据映射为键-值对生成中间结果。最后,中间结果按照键的排序进行合并和归并。
Hadoop组件
HDFS
HDFS组件用于存储数据,主要由NameNode,DataNode,SecondaryNameNode 组成
NameNode (nn): 存储文件的元数据,如文件名,文件目录结构,文件属性 (生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
DataNode(dn): 在本地文件系统存储文件块数据,以及块数据的校验。
SecondaryNameNode(2nn): 每隔一段时间对NameNode元数据进行备份
Yarn
Yarn资源调度负责硬件资源管理,主要由:ResourceManager,NodeManager,ApplicationMaster组成
ResourceManager (资源管理器):YARN集群中的中心调度器和资源管理器。负责整个集群的资源分配和调度 监控集群中的计算资源任务的运行状态
NodeManager (节点管理器):每个计算节点上运行的代理程序负责管理和监控节点上的资源和任务。接收来自RM的任务调度请求;启动、停止和监控任务的执行;发送节点的状态和可用资源报告
ApplicationMaster (应用程序管理器):每个应用程序在YARN中都有一个对应的AM.AppMaster负责协调和管理应用程序的执行。它与RM交互申请资源并监任务的执行。它还负责任务的划分和调度、容错和恢复、进度跟踪等。
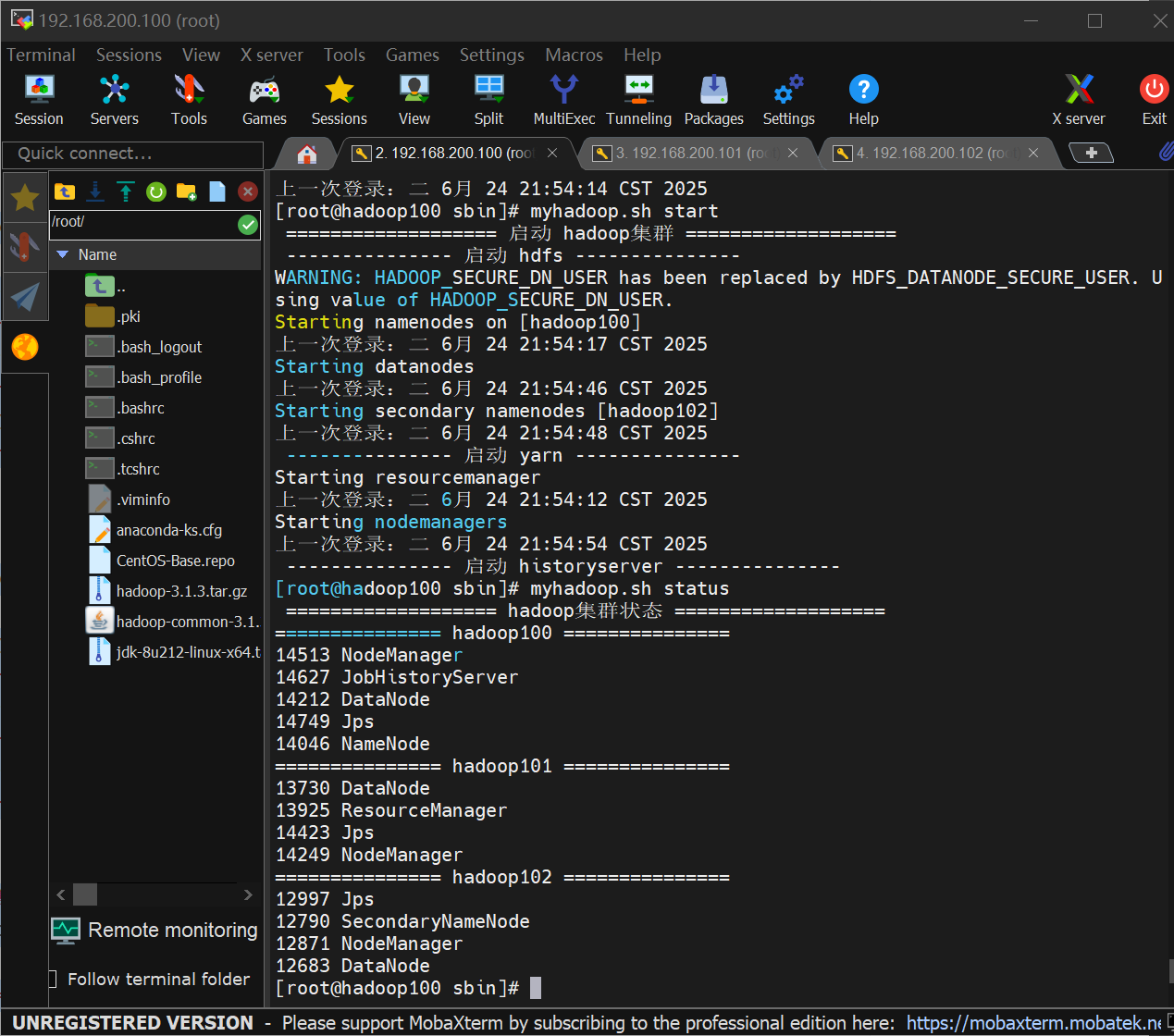
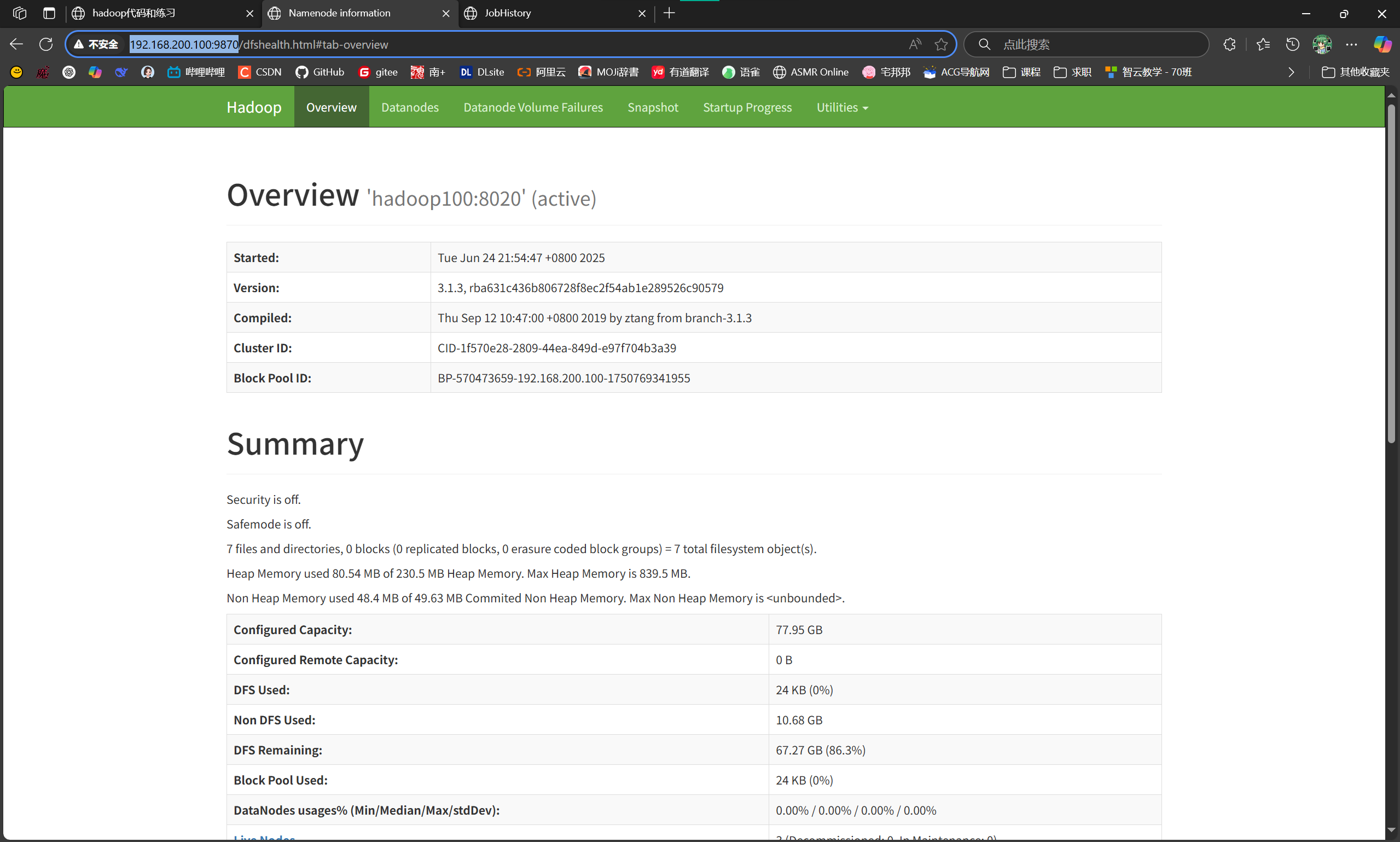
部署完成截图