
6.9总结:Pandas、爬虫
Python API 接⼝开发⽤法介绍
API ( Application Programming Interface )是应⽤程序接⼝的简称
1 | # 定义一个API接口 |
Pandas
Pandas 是 Python 语⾔的⼀个扩展程序库,⽤于数据分析。
Pandas 名字衍⽣⾃术语 “panel data” (⾯板数据)
Pandas 可以从各种⽂件格式⽐如 CSV 、 JSON 、 Excel
python 终端输⼊安装:
1 | pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas |
Pandas 数据结构 DataFrame
1 | data = {"Site":["Google", "Runoob", "Wiki"], "Age":[10, 12, 13],"sss":[22,33,44]} |
Pandas 处理 CSV ⽂件
1 | df = pd.read_csv("/root/shell/douban.csv") |
Pandas 处理 JSON
1 | import pandas as pd |
douban.txt 的文件处理
1 | #内嵌的方法 |
Pandas 处理 excel ⽂件
sheet_name 指定了读取 excel ⾥⾯的哪⼀个 sheet
usecols 指定了读取哪些列
nrows 指定了总共读取多少⾏
header 指定了列名在第⼏⾏,并且只读取这⼀⾏往下的数据
index_col 指定了 index 在第⼏列
engine=”openpyxl” 指定了使⽤什么引擎来读取 excel ⽂件
安装命令:
1 | import pandas as pd |
爬虫(requests)
安装
1 | pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple requests |
爬取一条数据
数据包的 headers ⾥⾯有我们需要的所有数据
数据包的 response ⾥⾯有我们要传递的 json 数据
1 | headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36"} |
爬取所有数据
1 | import requests |
pandas 分析处理数据
1 | content=response.json() |
练习
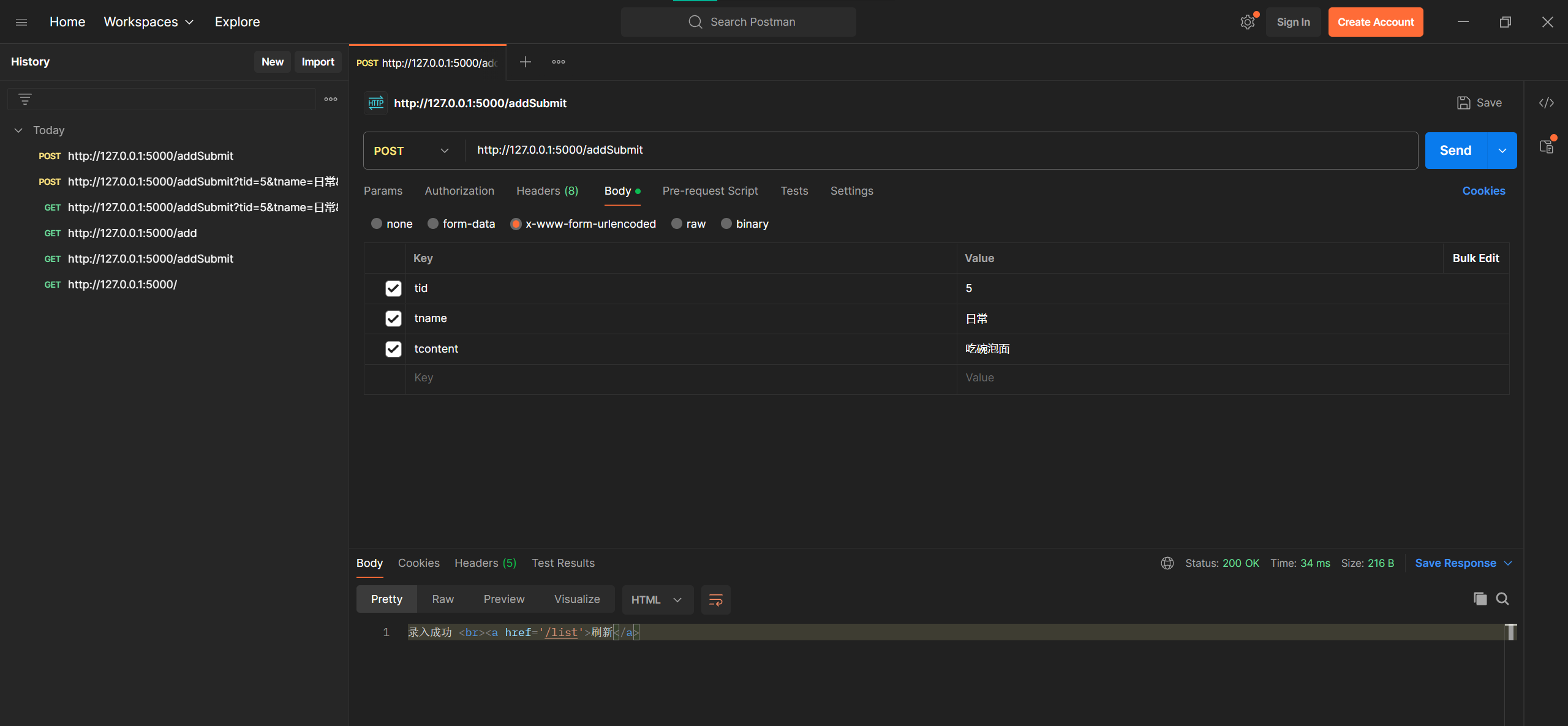
1.安装 postman ,测试添加电影类型接⼝是否正确
- 地址栏http://127.0.0.1:5000/addSubmit
- 设置POST传递方式
- 设置Body中的x-www-form-urlencoded
- 填写数据后点击send提交
1 | # 2.创建以⽇期时间为名字的⽇志⽂件,格式如 20230303102030.log |
1 | # 爬取⾄少五种电影类型(动画、科幻、恐怖)的电影追加到 csv ⽂件中 |
其他Python库
1. NumPy (Numerical Python)
- 核心功能:提供多维数组对象(
ndarray)、高效的数学函数、线性代数运算和随机数生成。 - 应用场景:科学计算、数据分析、机器学习(如 TensorFlow 依赖 NumPy 数组)。
- 优势:底层用 C 实现,运算速度极快,是众多科学库的基础。示例:
1 | import numpy as np |
2. Matplotlib
- 核心功能:2D 绘图库,支持线图、散点图、柱状图、饼图等多种可视化类型。
- 应用场景:数据可视化、论文图表、交互式绘图。
- 搭配工具:常与
pandas(数据处理)和seaborn(高级可视化)结合使用。 - 示例:
1 | import matplotlib.pyplot as plt |
3. unittest
- 核心功能:Python 内置的单元测试框架,支持测试用例、测试套件、断言等。
- 应用场景:软件开发中的测试驱动开发(TDD)、代码质量保障。
- 对比工具:类似
pytest,但unittest更适合初学者和小型项目。 - 示例:
1 | import unittest |
4. Setuptools
- 核心功能:Python 包开发工具,用于打包、分发和安装 Python 项目。
- 关键文件:
setup.py(定义包元信息)、requirements.txt(依赖列表)。 - 应用场景:发布开源库到 PyPI(Python Package Index)或内部使用。
- 示例:
1 | # setup.py |
5. Jupyter Notebook
- 核心功能:交互式计算环境,支持代码、Markdown 文本、公式和可视化混排。
- 应用场景:数据分析、机器学习实验、学术论文写作(如 Jupyter Lab)。
- 优势:实时运行代码,便于分享和演示,支持多种编程语言(通过内核)。
- 启动命令:
1 | jupyter notebook # 启动传统界面 |
总结
| 库名 | 主要用途 | 典型场景 |
|---|---|---|
| NumPy | 高性能数组计算 | 科学计算、AI 框架基础 |
| Matplotlib | 数据可视化 | 论文图表、交互式绘图 |
| unittest | 单元测试 | 代码质量保障 |
| Setuptools | 包打包与分发 | 发布 Python 库到 PyPI |
| Jupyter | 交互式计算与文档 | 数据分析、学术研究 |
相关推荐

2025-08-16
request和selenium(Python爬虫)
requests 和 selenium 是 Python 中两个常用的用于网络数据获取的工具,但它们的设计目标、使用场景和底层机制有显著不同。 入门指南 | Selenium 1. 基本概念 项目 requests selenium 类型 HTTP 库 浏览器自动化工具 功能 发送 HTTP 请求,获取响应 控制真实或虚拟浏览器进行页面操作 依赖 不依赖浏览器 依赖浏览器(如 Chrome、Firefox)或无头浏览器 2. 工作原理 requests: 直接与服务器进行 HTTP 通信。 只能获取服务器返回的原始 HTML 或 JSON 数据。 无法执行 JavaScript,无法与动态内容交互。 selenium: 启动一个真实的浏览器(或无头浏览器)。 完整加载页面,包括执行 JavaScript、加载 AJAX 内容、处理动态元素。 可模拟用户操作:点击、输入、滚动、等待等。 3. 使用场景对比 场景 推荐工具 原因 爬取静态网页(HTML 源码即所需内容) ✅ requests 快速、轻量、高效 爬取动态网页(内容由...

2025-07-28
医药器械法规AI项目(数据爬取部分)
项目需求实现输入商品信息接口,提交商品后根据现有法律法规判断商品是否符合法律法规(暂定) 医药器械网站NMPA:医疗器械法规文件CMDE:国家药品监督管理局医疗器械技术审评中心—-法规文件药智:政策法规数据库_药智数据 NMPA数据爬取(国家药品监督管理局)首页:医疗器械法规文件实现效果:爬取以上链接每篇文章的【索引号、标题、分类、日期、文章内容、链接】并导入数据库,若有附件则将其下载至对应路径(\attachments\nmpa\索引号\文章标题\),数据库保存其附件路径及附件数。 建表1234567891011121314CREATE TABLE `hwz_nmpa` ( `id` INT NOT NULL AUTO_INCREMENT COMMENT '自增主键', `index_id` VARCHAR(50) NOT NULL COMMENT '索引号', `title` VARCHAR(200) NOT NULL COMMENT '标题', `category` VARCHAR(50) COMMENT ...

2025-08-06
Python虚拟环境(conda)创建AI项目
condaConda配置完全指南-CSDN Conda 是一个开源的跨平台包管理与环境管理工具,广泛应用于数据科学、机器学习及 Python 开发领域。它不仅能帮助用户快速安装、更新和卸载第三方库,还能创建相互隔离的虚拟环境,解决不同项目之间的依赖冲突问题。例如,项目 A 依赖 Python 3.7 和 NumPy 1.0,而项目 B 需要 Python 3.10 和 NumPy 2.0,通过 conda 可分别创建独立环境,避免版本冲突。此外,conda 不仅支持 Python 包,还能管理 R、C/C++ 等非 Python 依赖,极大提升了跨语言开发的便捷性。 Anaconda 和 Miniconda Anaconda 是基于 conda 的完整发行版,预装了超过 250 个科学计算和数据分析的常用工具包(如 NumPy、Pandas、Jupyter),适合新手或需要快速搭建开发环境的用户。但 Anaconda 的安装包体积较大(约 3 GB),对存储空间有限的用户可能不够友好。 Miniconda 是 conda 的极简版本,仅包含核心的 conda 工具、P...

2025-08-07
影刀、扣子云AI应用:简历信息提取
影刀AI Power影刀AI Power使用AI提取简历信息的简单应用 提取图片简历信息工作流 扣子(coze)主页 - 扣子API 介绍 - 文档 - 扣子 创建智能体 代码实现 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153#!/bin/python3import osfrom PyPDF2 import PdfRe...

2025-06-26
Python连接Hive
hadoop上传数据12345hadoop dfs -mkdir /emphadoop dfs -put emp0901.txt /emp/hadoop dfs -mkdir /studenthadoop dfs -put student2.csv /student/ 处理student2.txt表12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849import jsondef transform_student_data(input_file, output_file): """ 将JSON格式的学生数据转换为CSV格式 参数: input_file: 输入JSON数据文件路径 output_file: 输出CSV文件路径 """ try: with open(input_file, 'r', encoding=&#x...
2025-07-02
网站日志文件清洗并上传到hive数据库
相关总结一、参数接收与文件校验1. 用户输入获取从命令行接收日期参数(格式:yyyymmdd) 1234dt = input("请输入参数: ")if not dt: print("请输入参数(格式:yyyymmdd)") exit() 2. 参数格式验证检查输入是否符合 8 位纯数字格式 12345678def test_value(dt, fpath): if len(dt) == 8 and dt.isdigit(): fname = f"{dt[0:4]}-{dt[4:6]}-{dt[6:8]}.log" fnamein = f'{fpath}/{fname}' return fname, fnamein else: print("输入参数格式不对: yyyy...

